End-to-end multilingual scene text spotting aims to integrate scene text detection and recognition into a unified framework. Actually, the accuracy of text recognition largely depends on the accuracy of text detection. Due to the lackage of benchmarks with adequate and high-quality character-level annotations for multilingual scene text spotting, most of the existing methods train on the benchmarks only with word-level annotations. However, the performance of multilingual scene text spotting are not that satisfied training on the existing benchmarks, especially for those images with special layout or words out of vocabulary. In this paper, we proposed a simple YOLO-like baseline named CMSTR for character-level multilingual scene text spotting simultaneously and efficiently. Technically, for each text instance, we represent the character sequence as ordered points and model them with learnable explicit point queries. After passing a single decoder, the point queries have encoded requisite text semantics and locations, thus can be further decoded to the center line, boundary, script, and confidence of text via very simple prediction heads in parallel. Furthermore, we show the surprisingly good extensibility of our method, in terms of character class, language type, and task. On the one hand, DeepSolo not only performs well in English scenes but also masters the Chinese transcription with complex font structure and a thousand-level character classes. On the other hand, based on the extensibility of DeepSolo, we launch DeepSolo++ for multilingual text spotting, making a further step to let Transformer decoder with explicit points solo for multilingual text detection, recognition, and script identification all at once.
| Published in | American Journal of Computer Science and Technology (Volume 7, Issue 3) |
| DOI | 10.11648/j.ajcst.20240703.12 |
| Page(s) | 71-81 |
| Creative Commons |
This is an Open Access article, distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution and reproduction in any medium or format, provided the original work is properly cited. |
| Copyright |
Copyright © The Author(s), 2024. Published by Science Publishing Group |
Multilingual Scene Text Image, Scene Text Recognition, Character-Level Annotations, Synthetic Benchmark
Origin label | Correct label | |
|---|---|---|
| VEICHLES | VEHICLES |
| Haugang | Hougang |
| SINCLARE | SKINCARE |
| WALKIN | WALKER |
Benchmark | Categories | Text Type | Train images | Test images | Word-level annotations | Character-level annotations |
|---|---|---|---|---|---|---|
SynthText [6] | 69 | Synthetic | 858,768 |
| 7,266,866 | 46,372,500 |
ICDAR 2013 [14] | 78 | Real | 229 | 233 | 1,944 |
|
ICDAR 2015 [13] | 86 | Real | 500 | 1,000 | 17,116 |
|
ICDAR 2017 MLT [20] | 3,885 | Real | 7,200 | 1,800 | 107,547 |
|
ICDAR 2017 RCTW [29] | 3,499 | Real | 11,154 | 1,000 | 65,248 |
|
ICDAR 2019 MLT [21] | 4,205 | Real | 9,000 | 1,000 | 111,998 |
|
ICDAR 2019 ReCTS [34] | 4,137 | Real | 20,000 | 5,000 | 146,952 | 440,027 |
TotalText [4] | 71 | Real | 1,255 | 300 | 13,708 |
|
IIIT5K [19] | 62 | Real | 2,000 | 3,000 | 5,000 | 18,268 |
SCUT-CTW1500 [16] |
| Real | 1,000 | 500 | 10,760 |
|
SVT [31] | 26 | Real | 100 | 250 | 904 |
|
CUTE80 [28] | 37 | Real | 288 |
| 288 |
|
SCUT_FORU_DB [35] | 72 (ENG) 2,116 (CHN) | Real | 1,162 (ENG) 1,861 (CHN) | (ENG) 355 (CHN) | 7,136 (ENG) 4,338 (CHN) | 22,555 (ENG) 21,393 (CHN) |
MLText (Ours) | 6,810 | Hybrid | 71,868 (ENG) 17,655 (CHN) | 3,000 (ENG) 4,666 (CHN) | 143,736 (ENG) (CHN) | 320,060 (ENG) 365,692 (CHN) |
Property type | Values |
|---|---|
Font style | eg.Arial.ttf, simkai.ttf |
Font size |
|
Word-level rotation |
|
Character-level rotation |
|
Trapezoidal transform |
|
Arc transform |
|
Occlusion area |
|
Light central point |
|
Lightness |
|
#Training Set | #Test Set | w/DIS | P | R | AP50 | AP |
|---|---|---|---|---|---|---|
ICDAR 2019 ReCTS | SCUT_FORU_DB (ENG) | 68.1 | 72.1 | 71.6 | 53.9 | |
√ | 68.4 | 71.9 | 71.9 | 53.2 | ||
IIIT5K-Words | 74.9 | 32.4 | 54.3 | 23.8 | ||
√ | 76.7 | 37.9 | 57.6 | 25.4 | ||
MLText | SCUT_FORU_DB (ENG) | 82.3 | 72.8 | 78.8 | 57.1 | |
√ | 82.8 | 72.0 | 79.0 | 56.6 | ||
IIIT5K-Words | 79.5 | 29.5 | 55.1 | 25.4 | ||
√ | 79.6 | 33 | 57.2 | 26.3 |
#Training Set | #Test Set | P | R | AP50 | AP |
|---|---|---|---|---|---|
SynthText | IIIT5K-Words | 68.2 | 46.6 | 48.5 | 15.1 |
SCUT_FORU_DB (ENG) | 58 | 70.1 | 71.4 | 33.8 | |
SCUT_FORU_DB (CHN) | - | - | - | - | |
ICDAR 2019 ReCTS | IIIT5K-Words | 69.8 | 42.5 | 44.9 | 17.1 |
SCUT_FORU_DB (ENG) | 71.8 | 71.9 | 71.3 | 49.8 | |
SCUT_FORU_DB (CHN) | 68.7 | 75.9 | 79.1 | 63.3 | |
MLText (Ours) | IIIT5K-Words | 75.3 | 70.1 | 64.6 | 58.5 |
SCUT_FORU_DB (ENG) | 82.8 | 72 | 79.1 | 56.4 | |
SCUT_FORU_DB (CHN) | 70.9 | 76.8 | 81.4 | 66 |
Datasets | ||||||||
|---|---|---|---|---|---|---|---|---|
Methods | TotalText | ICDAR 2019 ReCTS | FPS | Params (*106) | ||||
P | R | H | P | R | H | |||
SANHL_v1 [18] | - | - | - | 91.98 | 93.86 | 92.91 | 1.15 | 500.11 |
AE TextSpotter [32] | - | - | - | 93.38 | 89.98 | 91.65 | 0.89 | 352.97 |
ABCNetv2 [17] | 70.2 | 82.1 | 75.7 | 92.89 | 87.91 | 90.33 | 1.58 | 50.84 |
SwinText [11] | - | - | 88.0 | 94.1 | 87.1 | 90.4 | 0.13 | 176.77 |
ESTextSpotter [10] | 92.0 | 88.1 | 90.0 | 91.3 | 94.1 | 92.7 | 4.3 | 49.84 |
DeepSolo++ [33] | 92.9 | 87.4 | 90.0 | 92.55 | 89.01 | 90.74 | 1.11 | 64.4 |
CSTDRNet (Ours) | 93.1 | 86.7 | 90.5 | 93.1 | 94.3 | 93.9 | 6.67 | 48.85 |
| [1] | Baek Y, Shin S, Baek J, et al. Character region attention for text spotting [C]//Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part XXIX 16. Springer International Publishing, 2020: 504-521. |
| [2] | Bochkovskiy A. Yolov4: Optimal speed and accuracy of object detection [J]. arxiv preprint arxiv:2004.10934, 2020. |
| [3] | Bušta M, Patel Y, Matas J. E2e-mlt-an unconstrained end-to-end method for multi-language scene text [C]// Computer Vision–ACCV 2018 Workshops: 14th Asian Conference on Computer Vision, Perth, Australia, December 2–6, 2018, Revised Selected Papers 14. Springer International Publishing, 2019: 127-143. |
| [4] | Ch’ng C K, Chan C S, Liu C L. Total-text: toward orientation robustness in scene text detection [J]. International Journal on Document Analysis and Recognition (IJDAR), 2020, 23(1): 31-52. |
| [5] | Yao C, Bai X, Liu W, et al. Detecting texts of arbitrary orientations in natural images [C]//2012 IEEE conference on computer vision and pattern recognition. IEEE, 2012: 1083-1090. |
| [6] | Gupta A, Vedaldi A, Zisserman A. Synthetic data for text localisation in natural images [C]// Proceedings of the IEEE conference on computer vision and pattern recognition. 2016: 2315-2324. |
| [7] | He K, Zhang X, Ren S, et al. Spatial pyramid pooling in deep convolutional networks for visual recognition [J]. IEEE transactions on pattern analysis and machine intelligence, 2015, 37(9): 1904-1916. |
| [8] | Huang J, Pang G, Kovvuri R, et al. A multiplexed network for end-to-end, multilingual OCR [C]// Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2021: 4547-4557. |
| [9] | Huang J, Liang K J, Kovvuri R, et al. Task grouping for multilingual text recognition [C]// European Conference on Computer Vision. Cham: Springer Nature Switzerland, 2022: 297-313. |
| [10] | Huang M, Zhang J, Peng D, et al. Estextspotter: Towards better scene text spotting with explicit synergy in transformer [C]// Proceedings of the IEEE/CVF International Conference on Computer Vision. 2023: 19495-19505. |
| [11] | Huang M, Liu Y, Peng Z, et al. Swintextspotter: Scene text spotting via better synergy between text detection and text recognition [C]//proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2022: 4593-4603. |
| [12] | Jaderberg M, Simonyan K, Vedaldi A, et al. Synthetic data and artificial neural networks for natural scene text recognition [J]. arxiv preprint arxiv:1406.2227, 2014. |
| [13] | Karatzas D, Gomez-Bigorda L, Nicolaou A, et al. ICDAR 2015 competition on robust reading [C]// 2015 13th international conference on document analysis and recognition (ICDAR). IEEE, 2015: 1156-1160. |
| [14] | Karatzas D, Shafait F, Uchida S, et al. ICDAR 2013 robust reading competition [C]// 2013 12th international conference on document analysis and recognition. IEEE, 2013: 1484-1493. |
| [15] | Li H, Xiong P, An J, et al. Pyramid attention network for semantic segmentation [J]. arxiv preprint arxiv:1805.10180, 2018. |
| [16] | Liu Y, Jin L, Zhang S, et al. Curved scene text detection via transverse and longitudinal sequence connection [J]. Pattern Recognition, 2019, 90: 337-345. |
| [17] | Liu Y, Shen C, Jin L, et al. Abcnet v2: Adaptive bezier-curve network for real-time end-to-end text spotting [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2021, 44(11): 8048-8064. |
| [18] | Liu Y, Zhang S, Jin L, et al. Omnidirectional scene text detection with sequential-free box discretization [C]// Proceedings of the 28th International Joint Conference on Artificial Intelligence. 2019: 3052-3058. |
| [19] | Mishra A, Alahari K, Jawahar C V. Scene text recognition using higher order language priors [C]//BMVC-British machine vision conference. BMVA, 2012. |
| [20] | Nayef N, Yin F, Bizid I, et al. Icdar2017 robust reading challenge on multi-lingual scene text detection and script identification-rrc-mlt [C]// 2017 14th IAPR international conference on document analysis and recognition (ICDAR). IEEE, 2017, 1: 1454-1459. |
| [21] | Nayef N, Patel Y, Busta M, et al. Icdar2019 robust reading challenge on multi-lingual scene text detection and recognition—rrc-mlt-2019 [C]//2019 International conference on document analysis and recognition (ICDAR). IEEE, 2019: 1582-1587. |
| [22] | Netzer Y, Wang T, Coates A, et al. Reading digits in natural images with unsupervised feature learning [C]// NIPS workshop on deep learning and unsupervised feature learning. 2011, 2011(2): 4. |
| [23] | Peng D, Jin L, Liu Y, et al. Pagenet: Towards end-to-end weakly supervised page-level handwritten Chinese text recognition [J]. International Journal of Computer Vision, 2022, 130(11): 2623-2645. |
| [24] | Qian Q, Jin R, Yi J, et al. Efficient distance metric learning by adaptive sampling and mini-batch stochastic gradient descent (SGD) [J]. Machine Learning, 2015, 99: 353-372. |
| [25] | Redmon J, Farhadi A. YOLO9000: better, faster, stronger [C]// Proceedings of the IEEE conference on computer vision and pattern recognition. 2017: 7263-7271. |
| [26] | Redmon J. Yolov3: An incremental improvement [J]. arxiv preprint arxiv:1804.02767, 2018. |
| [27] | Redmon J, Divvala S, Girshick R, et al. You only look once: Unified, real-time object detection [C]// Proceedings of the IEEE conference on computer vision and pattern recognition. 2016: 779-788. |
| [28] | Risnumawan A, Shivakumara P, Chan C S, et al. A robust arbitrary text detection system for natural scene images [J]. Expert Systems with Applications, 2014, 41(18): 8027-8048. |
| [29] | Shi B, Yao C, Liao M, et al. Icdar2017 competition on reading chinese text in the wild (rctw-17) [C]// 2017 14th iapr international conference on document analysis and recognition (ICDAR). IEEE, 2017, 1: 1429-1434. |
| [30] | Wang C Y, Liao H Y M, Wu Y H, et al. CSPNet: A new backbone that can enhance learning capability of CNN [C]// Proceedings of the IEEE/CVF conference on computer vision and pattern recognition workshops. 2020: 390-391. |
| [31] | Wang K, Babenko B, Belongie S. End-to-end scene text recognition [C]// 2011 International conference on computer vision. IEEE, 2011: 1457-1464. |
| [32] | Wang W, Liu X, Ji X, et al. Ae textspotter: Learning visual and linguistic representation for ambiguous text spotting [C]//Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part XIV 16. Springer International Publishing, 2020: 457-473. |
| [33] | Ye M, Zhang J, Zhao S, et al. DeepSolo++: Let Transformer Decoder with Explicit Points Solo for Multilingual Text Spotting [J]. arxiv preprint arxiv:2305.19957, 2023. |
| [34] | Rui Zhang et al. “ICDAR 2019 Robust Reading Challenge on Reading Chinese Text on Signboard”. In: 2019 International Conference on Document Analysis and Recognition (ICDAR). 2019. |
| [35] | Zhang S, Lin M, Chen T, et al. Character proposal network for robust text extraction [C]// 2016 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2016: 2633-2637. |
APA Style
Ma, S., Xu, Y. (2024). Rethinking Multilingual Scene Text Spotting: A Novel Benchmark and a Character-Level Feature Based Approach. American Journal of Computer Science and Technology, 7(3), 71-81. https://doi.org/10.11648/j.ajcst.20240703.12
ACS Style
Ma, S.; Xu, Y. Rethinking Multilingual Scene Text Spotting: A Novel Benchmark and a Character-Level Feature Based Approach. Am. J. Comput. Sci. Technol. 2024, 7(3), 71-81. doi: 10.11648/j.ajcst.20240703.12
AMA Style
Ma S, Xu Y. Rethinking Multilingual Scene Text Spotting: A Novel Benchmark and a Character-Level Feature Based Approach. Am J Comput Sci Technol. 2024;7(3):71-81. doi: 10.11648/j.ajcst.20240703.12
@article{10.11648/j.ajcst.20240703.12,
author = {Siliang Ma and Yong Xu},
title = {Rethinking Multilingual Scene Text Spotting: A Novel Benchmark and a Character-Level Feature Based Approach
},
journal = {American Journal of Computer Science and Technology},
volume = {7},
number = {3},
pages = {71-81},
doi = {10.11648/j.ajcst.20240703.12},
url = {https://doi.org/10.11648/j.ajcst.20240703.12},
eprint = {https://article.sciencepublishinggroup.com/pdf/10.11648.j.ajcst.20240703.12},
abstract = {End-to-end multilingual scene text spotting aims to integrate scene text detection and recognition into a unified framework. Actually, the accuracy of text recognition largely depends on the accuracy of text detection. Due to the lackage of benchmarks with adequate and high-quality character-level annotations for multilingual scene text spotting, most of the existing methods train on the benchmarks only with word-level annotations. However, the performance of multilingual scene text spotting are not that satisfied training on the existing benchmarks, especially for those images with special layout or words out of vocabulary. In this paper, we proposed a simple YOLO-like baseline named CMSTR for character-level multilingual scene text spotting simultaneously and efficiently. Technically, for each text instance, we represent the character sequence as ordered points and model them with learnable explicit point queries. After passing a single decoder, the point queries have encoded requisite text semantics and locations, thus can be further decoded to the center line, boundary, script, and confidence of text via very simple prediction heads in parallel. Furthermore, we show the surprisingly good extensibility of our method, in terms of character class, language type, and task. On the one hand, DeepSolo not only performs well in English scenes but also masters the Chinese transcription with complex font structure and a thousand-level character classes. On the other hand, based on the extensibility of DeepSolo, we launch DeepSolo++ for multilingual text spotting, making a further step to let Transformer decoder with explicit points solo for multilingual text detection, recognition, and script identification all at once.
},
year = {2024}
}
TY - JOUR T1 - Rethinking Multilingual Scene Text Spotting: A Novel Benchmark and a Character-Level Feature Based Approach AU - Siliang Ma AU - Yong Xu Y1 - 2024/09/06 PY - 2024 N1 - https://doi.org/10.11648/j.ajcst.20240703.12 DO - 10.11648/j.ajcst.20240703.12 T2 - American Journal of Computer Science and Technology JF - American Journal of Computer Science and Technology JO - American Journal of Computer Science and Technology SP - 71 EP - 81 PB - Science Publishing Group SN - 2640-012X UR - https://doi.org/10.11648/j.ajcst.20240703.12 AB - End-to-end multilingual scene text spotting aims to integrate scene text detection and recognition into a unified framework. Actually, the accuracy of text recognition largely depends on the accuracy of text detection. Due to the lackage of benchmarks with adequate and high-quality character-level annotations for multilingual scene text spotting, most of the existing methods train on the benchmarks only with word-level annotations. However, the performance of multilingual scene text spotting are not that satisfied training on the existing benchmarks, especially for those images with special layout or words out of vocabulary. In this paper, we proposed a simple YOLO-like baseline named CMSTR for character-level multilingual scene text spotting simultaneously and efficiently. Technically, for each text instance, we represent the character sequence as ordered points and model them with learnable explicit point queries. After passing a single decoder, the point queries have encoded requisite text semantics and locations, thus can be further decoded to the center line, boundary, script, and confidence of text via very simple prediction heads in parallel. Furthermore, we show the surprisingly good extensibility of our method, in terms of character class, language type, and task. On the one hand, DeepSolo not only performs well in English scenes but also masters the Chinese transcription with complex font structure and a thousand-level character classes. On the other hand, based on the extensibility of DeepSolo, we launch DeepSolo++ for multilingual text spotting, making a further step to let Transformer decoder with explicit points solo for multilingual text detection, recognition, and script identification all at once. VL - 7 IS - 3 ER -
School of Computer Science and Engineering, South China University of Technology, Guangzhou, China
Biography: Siliang Ma is a Ph.D student at the School of Computer Science and Engineering at South China University of Technology. He received his B.E. degree from South China Agricultual University in 2019. He is the President of CCF South China University of Technology Student Chapter. His research interests include deep learning, pattern recognition, and text image processing.

School of Computer Science and Engineering, South China University of Technology, Guangzhou, China; Pengcheng Laboratory, Shenzhen, China
Biography: Yong Xu received the B.S., M.S., and Ph.D. degrees in mathematics from Nanjing University, Nanjing, China, in 1993, 1996, and 1999, respectively. He was a Postdoctoral Research Fellow of computer science with the South China University of Technology, Guangzhou, China, from 1999 to 2001, where he became a Faculty Member and is currently a Professor with the School of Computer Science and Engineering. He is the vice president of South China University of Technology and the Dean of Guangdong Big Data Analysis and Processing Engineering & Technology Research Center. He is also a member of the Peng Cheng Laboratory. His current research interests include computer vision, pattern recognition, image processing, and big data. He is a senior member of the IEEE Computer Society and the ACM. He has received the New Century Excellent Talent Program of MOE Award.


Figure 1. Multilingual scene text images from SCUT_FORU_DB [35], IIIT5K [19], TotalText [4] and SCUT-CTW1500 [16] with various layout.
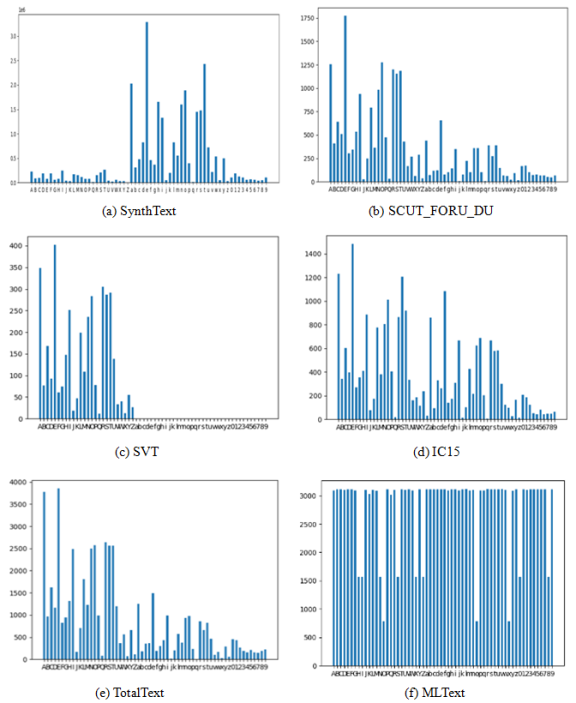
Figure 2. The character frequency of the existing public scene text image dataset is compared with MLText.
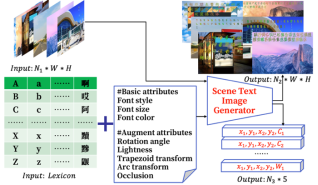
Figure 3. Generation process of our proposed scene text spotting benchmark MLText.
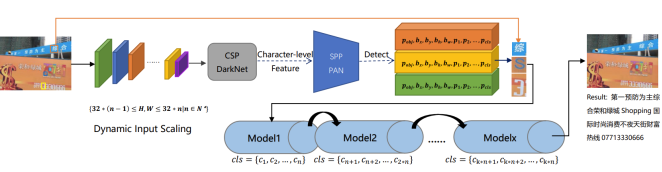
Figure 4. Architecture of our proposed character-level scene text spotting model CSTDRNet. In this framework, we generate three bounding boxes for each pixel, denotes the probability of object, and denote the centroid point’s coordinate of each individual bounding box, and denote the height and width of each individual bounding box, denotes the probability of each category.

Figure 5. Scene text spotting results on images from TotalText, ICDAR 2019 ReCTS and SCUT_FORU_DB.
Information





