2. Methodology
2.1. Reduced Order Modeling (ROM)
Reduced order modeling originally known as Model Order Reduction (MOR), is another solution. ROM was first developed in the field of system control to reduce the complexity of a dynamic system while preserving the input–output characteristic behavior as much as possible. Later, it captured the attention of mathematicians and researchers in the field of numerical simulation and today is a flourishing area of research in mathematics, physics, and engineering.
As a solution to computation time and storage capacity for complex processes, ROM captures the essential features of a structure and produces reliable outcomes with sufficient accuracy. In this way, it is even possible to have online predictions for the system behavior within acceptable calculation time to optimize the system.
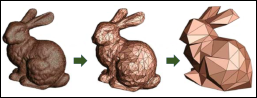
Figure 1, taken from Harvard University – Microsoft research, shows a conceptual schematic of ROM. It shows that sometimes less details may be required to describe a model, just like the rabbit in the Stanford Bunny graphical example that can be recognized with a few facets. Although this example does not reflect the mathematical operations behind the ROM, it is a very simple graphical example to demonstrate the whole idea of reduced order modeling.
Figure 1. Stanford Bunny Graphical Example to Demonstrate the Overall Idea of REDUCED Order Modeling (ROM).
Approximating a function by a few trigonometrical functions was introduced by Fourier in 1807. Padé in 1890 introduced the Padé approximation which approximates a function by the ratio of two polynomials. These can be considered as the first examples of mathematical model reduction. In linear algebra, Lanczos method was among the first who tried to reduce a matrix in tridiagonal form in 1950
| [8] | Lanczos, C. 1950. "An iteration method for the solution of the eigenvalue problem of linear differential and integral operators." Journal of Research of the National Bureau of Standards 45 (4): 255-282.
https://10.6028/jres.045.026 |
[8]
. Around the same time, in 1951, a paper by Arnoldi was published in which he explained how a smaller matrix can be a good approximation of a larger one
| [1] | Arnoldi, W E. 1951. "The principle of Minimized Iterations in the Solution of the Matrix Eigenvalue Problem." Quarterly of Applied Mathematics 9(1): 17-29.
http://www.jstor.org/stable/43633863 |
[1]
. But it was not until 80s and 90s of the last century that fundamental methods of ROM were published.
In 1981, Truncated Balanced Realization (TBR) method was introduced by Moore
| [9] | Moore, B. 1981. "Principal component analysis in linear systems: Controllability, observability, and model reduction." IEEE Transactions on Automatic Control 26(1): 17-32.
https://10.1109/TAC.1981.1102568 |
[9]
which was followed by Glover’s work with Henkel-Norm method in 1984
| [6] | Glover, K. 1984. "All optimal Hankel-norm approximations of linear multivariable systems and their L, ∞ -error bounds." International Journal of Control 39(6): 1115-1193.
https://10.1080/00207178408933239 |
[6]
. Proper Orthogonal Decomposition (POD) was introduced by Sirovich in 1986
| [19] | Sirovich, L. 1986. "TURBULENCE AND THE DYNAMICS OF COHERENT STRUCTURESPART I: COHERENT STRUCTURES." Quarterly of Applied Mathematics 45 (1987): 561-571. https://www.jstor.org/stable/43637457 |
[19]
. Asymptotic Waveform Evaluation (AWE) was published by Pillage in 1990
| [12] | Pillage, L T, and R A Rohrer. 1990. "Asymptotic waveform evaluation for timing analysis." IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems 9(4): 352-366. https://10.1109/43.45867 |
[12]
as a reduction method using Padé approximation and in 1993, Freund proposed his Padé via Lancsoz (PVL) method
| [4] | Feldmann, P, and R W Freund. 1993. "Efficient linear circuit analysis by Pade approximation via the Lanczos process." IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems 14(5): 639-649.
https://10.1109/43.384428 |
[4]
.
There are many other old and new ROM methods and reviewing all of them is beyond the scope of this study. In the following subsection, the Krylov subspace methods will be briefly reviewed as they form the foundation of reduced space. Then, the rest of the section will cover the projection base method in depth since this is the method used in this research work.
2.2. Krylov Subspace Methods
Krylov subspace methods are those methods that try to find the “best” approximate solution for a linear set of equation () in a Krylov subspace. The basic idea is simple to explain. Since are vectors in a n-dimensional space, it can be claimed that vectors in the set of are also in the same space. If the first n+1 of these vectors are considered, it is known that they are dependent because in a n-dimensional space, there are only n independent vectors. Therefore, there is a set of coefficients that satisfy
(1)
The coefficients, , can be any real number and at least two of them are non-zero. If is the first non-zero coefficient, then the above equation can be rewritten as
(2)
Because exists, both sides can be multiplied by resulting in
(3)
The above equation tells us that the solution exists in a subspace of the space spanned by vectors. In addition, if there are small values of that can be ignored, the solution can be approximated with a smaller number of vectors as
(4)
This equation constructs a subspace called Krylov subspace defined as
(5)
Now the question is how to decide for the “best” approximation. Below are the main categories:
1) Minimizing residual in Krylov subspace (CG).
2) Minimizing residual second norm in Krylov subspace . (Generalized Minimal RESidual (GMRES), MINimal RESidual (MINRES)).
3) Minimizing residual in a different Krylov subspace (BiCG).
4) Minimizing the error of estimation for in Krylov subspace (SYMmetric Lanczos Q-iteration (SYMMLQ)).
Table 1 summarize all the methods used in Krylov subspace reduction.
Table 1. Summary of Krylov Subspace Methods.
Method | System Specification | Introduced by |
Lancsoz / PVL | Hermitian | Lancsoz | [8] | Lanczos, C. 1950. "An iteration method for the solution of the eigenvalue problem of linear differential and integral operators." Journal of Research of the National Bureau of Standards 45 (4): 255-282.
https://10.6028/jres.045.026 |
[8] | [4] | Feldmann, P, and R W Freund. 1993. "Efficient linear circuit analysis by Pade approximation via the Lanczos process." IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems 14(5): 639-649.
https://10.1109/43.384428 |
[4] |
Arnoldi / PRIMA | Non-Hermitian | Arnoldi / Odabasioglu | [1] | Arnoldi, W E. 1951. "The principle of Minimized Iterations in the Solution of the Matrix Eigenvalue Problem." Quarterly of Applied Mathematics 9(1): 17-29.
http://www.jstor.org/stable/43633863 |
[1] |
Conjugate Gradient (CG) | Symmetric positive definite | Hestenes (1952) | [7] | Hestenes, M, and E Stiefel. 1952. "Methods of conjugate gradients for solving linear systems." Journal of Research of the National Bureau of Standards 49(6).
https://10.6028/jres.049.044 |
[7] |
MINRES / SYMMLQ | Symmetric indefinite | Paige (1975) | [11] | Paige, C C, and M A Saunders. 1975. "Solution of Sparse Indefinite Systems of Linear Equations." SIAM Journal on Numerical Analysis 12(4): 617-629.
https://doi.org/10.1137/0712047 |
[11] |
GMRES | Non-Symmetric | Saad (1986) | [17] | Saad, Y, and M H Schultz. 1986. "GMRES: A Generalized Minimal Residual Algorithm for Solving Nonsymmetric Linear Systems." SIAM Journal on Scientific and Statistical Computing 7(3): 856-869. https://doi.org/10.1137/0907058 |
[17] |
Bi-Conjugate Gradient (BiCG) | Non-Symmetric | Fletcher (1976) | [5] | Fletcher, R. 1976. "Conjugate gradient methods for indefinite systems." Springer - Lecture Notes in Mathematics - Numerical Analysis by: Watson G. A. 506.
https://doi.org/10.1007/BFb0080116 |
[5] |
2.3. Proper Orthogonal Decomposition (POD)
Proper orthogonal decomposition is a projection-based method meaning that the reduced space is a projection of the Full Order Model (FOM) space using a transfer function. This method is popular in Computational Fluid Dynamic (CFD) applications and is gaining popularity among all other engineering disciplines including system controls as well. The strongest advantage of the POD method is its applicability to nonlinear Partial Differential Equations (PDEs)
| [13] | Polyanin, A D, and V Zaitsev. 2012. Handbook of Nonlinear Partial Differential Equations. Second Edition. CRC Press. |
| [14] | Rathinam, M., and L. R. Petzold. 2003. “A New Look at Proper Orthogonal Decomposition.” SIAM Journal on Numerical Analysis 41(5): 1893–1925.
https://doi.org/10.1137/S0036142901389049 |
[13, 14]
.
The basic underlying idea of the POD method is that the response of a system at a given time contains all the characteristics and essential behaviour of that system. So, POD collects snapshots of the system at various times and extracts the most important aspects of the behavior in the output, or in the state variables, and preserves those by constructing a reduced space from those snapshots in which output, or state variables, can be estimated with reasonable accuracy.
Finding an orthonormal basis for a reduced order space is an important part of the POD approach. Therefore, in the followings some basics of the POD approach like; projection, determining a n-dimensional space and its orthonormal basis, and eigenvalue problems will be reviewed briefly. Then, POD will be explained in more detail using these basics.
2.3.1. Normal and Oblique Projection
Considering two vectors of and , a matrix of real numbers like can act as a transformation or linear mapping matrix between the two vectors if
(6)
With the transformation of to as in the above, , each row of A can be considered as vectors that m-dimensional space of is spanning over and each column of A can be considered as vectors that n-dimensional space of is spanning over. As the left multiplication of a matrix with a vector is usually used throughout this work, these two interpretations of linear mapping frequently will be used too.
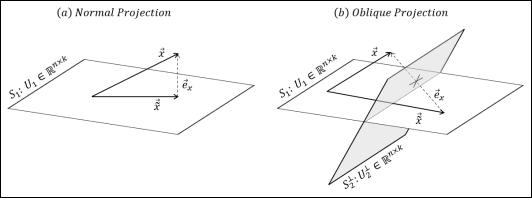
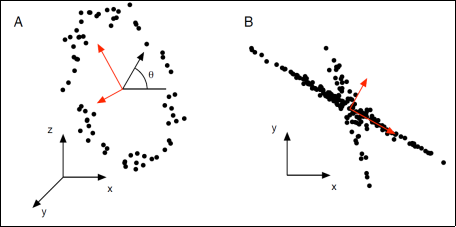
Figure 2 shows a schematic of normal and oblique projections of a vector
to
. Assuming space
spans over a full-column rank matrix
and the normal space to
,
, spans over full-column rank matrix of
, one can write the equations below for the definition of normal and oblique projections:
(7)
Figure 2. Normal and Oblique Projections.
2.3.2. Gram-Schmidt Orthonormalization
A n-dimensional space can be defined with a set of independent vectors like , similar to what was defined for a Krylov subspace. As in the example of Krylov space, these vectors are not orthogonal, meaning that there are not two vectors that can satisfy: . Now if the matrix is constructed, this matrix is called “orthonormal” if it satisfies: .
Gram-Schmidt process is a procedure that converts a non-orthonormal basis matrix into an orthonormal one. This conversion has many benefits resulting from the above identity and will be used throughout this work. The procedure is simple and follows
(8)
Applying the above equation on will result in which will satisfy: .
2.3.3. Eigenvalue Methods
Eigenvalue methods are those methods that solve for eigenvalues of a matrix in an eigenvalue problem; in which are called eigenvectors corresponding to eigenvalues. The eigenvalue problem of can be solved by direct or iterative methods. Arnoldi, QR decomposition and Singular Value Decomposition (SVD) are among those eigenvalue iterative methods that are used extensively in ROM applications. Arnoldi and QR decomposition use Gram-Schmidt type algorithm to create a sequence which will converge into eigenvalues. SVD is not directly an eigenvalue algorithm, but it is used in POD in a way that it results in determining eigenvalues, therefore it will be explained that how SVD works and how it will produce eigenvalues since its basics will be used in this research work.
SVD algorithm factorizes a general rectangular matrix like into three matrices as
(9)
is an orthonormal matrix that can be a basis for an n-dimensional space.
is a diagonal matrix containing singular values of A which are square root of non-negative eigenvalues of A (). The number of non-zero singular values in this diagonal matrix is equal to the rank of A.
is an orthonormal matrix that can be a basis for an m-dimensional space.
A very useful property of the singular value decomposition of Equation (
9) is the result of A
TA or AA
T as shown in equations below:
(10)
Multiplying both sides of the AAT (or similarly for ATA) by U gives
The above equation indicates that all eigenvalues of
reside in
. This property will be used later for the POD method and the application. At this point all the prerequisites to explain the POD method have been covered properly. In the following sections, Proper Orthogonal Decomposition (POD) in particle-in-fluid flow, which has never been done before, will be covered and it will be shown how to combine this technique with the previous nonintrusive formulation introduced Razavi in 2022 to build a predictive model that runs several orders of magnitude faster than the full order model
| [15] | Razavi, Seyed Mahdi, Zargar, Zeinab, Farouq Ali, S. M., and Mohamed Y. Soliman. 2022. "Development of a New Progressive Nonintrusive Theory to Reduce Computation Time with Particle-in-Fluid Flow Application." SPE Journal (5): 3063-3082. https://doi.org/10.2118/209804-PA |
[15]
. Therefore, the POD steps introduced before will be reviewed again but more in the context of particle-in-fluid flow. The POD in this study will be performed in three major steps and then will be combined with the nonintrusive method explained by the author to establish a new ROM method that can reduce the computation time significantly. The resulting formulation is then applied to a solid blower example to prove the concept.
2.4. Data Construction in Full Space
The reduced space (reduced order space) is hidden inside snapshot data taken in the full space. A snapshot can be defined as a vector of primary variables or state variables taken at a certain time while simulating or measuring a process. The snapshots data has seen the system behavior and experienced the state variables variations. When state variables show erratic variations and change significantly during a run, a wider distribution of numbers and higher standard deviations is observed. Such a system needs more principal components to be explained in comparison to a system that does not show much of variation in its state variables.
The above general rule applies to each individual state variable since some variables may experience wider changes than others. This becomes clearer with an example. In a container, particles positions (state variables x and y in a two-dimensional model) cannot go beyond the container limits, but the velocity components can go from a very small value or zero to a very high value and can experience a wide variation. This is the common problem of scaling and normalization is used in this study as the solution and all calculations are performed on normalized variables. Therefore, rather than the scale of changes, the concern is more about the rate of changes. Particle location from one time step to another does not change widely because time step does not allow a particle to travel far but velocity, which is mostly dictated by collisions, can change erratically. This behavioral difference in state variables forces us to separate variables and find a reduced space for each separately instead of finding one reduced space for all state variables. This is a common practice in most POD applications.
Finding one reduced space for each state variable results in some changes in the shape of the equations and matrices that were introduced before. The transformation equation between full and reduced order spaces is
(12)
Here and are state variable is full and reduced spaces respectively. is the number of state variables in any snapshot in full space dimension. is the number of particles in any snapshot, is the number of state variables for each particle and is the number of principal components in any snapshot.
The above equation is written for a case that all state variables are reduced using the same transformation matrix or basically to the same reduced space. In this case, the ordering of state variables inside
becomes irrelevant and
will be shaped in a way that preserves the ordering between reduced space and full space. But how will these equations change or how each snapshot state variable vector is formed if there is a different transformation matrix for each state variable? Equation (
13) shows how the transformation equation will look like when there is one transformation matrix for each state variable.
(13)
Where , , and are projection matrices for position and velocity x and y components respectively.
As shown in the above equation, the snapshot state vector is constructed starting with all x values first, then all y values and so on. There is another way of configuration as
(14)
The projection/transformation matrix format in Equation (
13) is easier to build, but the state vector configuration in Equation (
14) is more convenient to work with. Computationally, the projection matrix is built once, but state variable vectors are used many times. So, it is preferred to continue with a convention that is easier to implement in terms of configuring state variable vectors. This requires reconfiguration of the projection matrix from its convenient form in Equation (
13).
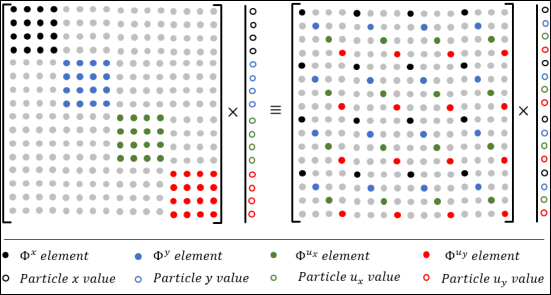
Figure 3 shows a schematic of this reconfiguration for a small example.
Figure 3. Reconfiguration of the Projection Matrix in Order to be Consistent with State Variable Vector Ordering.
Another major concern in constructing the projection matrix from snapshot data is the number of available data points. It is known that finding the reduced space is an eigenvalue problem represented by
| [15] | Razavi, Seyed Mahdi, Zargar, Zeinab, Farouq Ali, S. M., and Mohamed Y. Soliman. 2022. "Development of a New Progressive Nonintrusive Theory to Reduce Computation Time with Particle-in-Fluid Flow Application." SPE Journal (5): 3063-3082. https://doi.org/10.2118/209804-PA |
[15].
(15)
Where is the matrix of snapshot data, is eigenvectors, is eigenvalues, is total number of snapshots used in building X and is the number of state variables in any snapshot – Full space dimension.
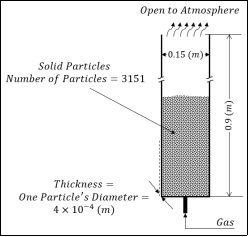
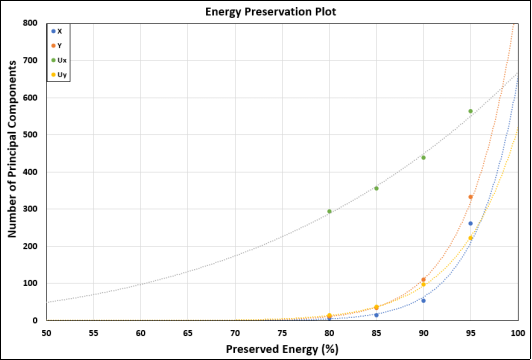
Based on the above equation, matrix R has the size of Nsn×Nsn. Such a matrix has Nsn number of eigenvalues and eigenvectors, meaning that maximum number of principal components explaining the variation in state variables can reach Nsn. This shows the importance of the available number of snapshots in building snapshot matrix X. In the gas blower example which will be presented later as a case study, there are 3151 particles and four state variables for each particle which makes the size of state variable vector for a snapshot 12,604. Therefore, in each snapshot there is a 12604-dimensional vector in full space. If 10 snapshots are gathered, there will be an ‘R’ matrix with size of 10×10 and a reduced space that at its maximum has 10 dimensions. In other words, a 12,604-dimensional space is being explained with only 10 principal components! It is possible to do it mathematically even with less than 10 number of components, but when the number of principal components is low, each of the corresponding eigenvalues carries a big weight in preserving the system energy. This means that if one is dropped, suddenly 10% or 25% of the system energy will be lost. Therefore, it is preferable to increase the number of available components to at least 20 or 30 so that each does not carry a big weight in preserving the system energy and the smallest ones may preserve less than 1% of the energy and can be easily ignored.
The above concept enforces using at least 20 to 30 snapshots to build the snapshot data matrix X. Two families of snapshots are available. First, those that are along the closest run (available simulations or measurements) trajectory which is the run that its location in the input space is the closet to the prediction run (simulation) and second, those that are available in the neighboring runs which are usually runs that are not as close but can be used to calculate the required spatial gradients
| [15] | Razavi, Seyed Mahdi, Zargar, Zeinab, Farouq Ali, S. M., and Mohamed Y. Soliman. 2022. "Development of a New Progressive Nonintrusive Theory to Reduce Computation Time with Particle-in-Fluid Flow Application." SPE Journal (5): 3063-3082. https://doi.org/10.2118/209804-PA |
[15]
. Therefore, the total number of available snapshots will be
Where is the number of available snapshots in the closest run and is the number of neighboring runs.
Usually more than 10 snapshots are selected among the available frames and there are commonly at least 3 neighboring runs, so maximum number of components can easily reach 40. But it is always essential to keep track of the available data and how principal components are limited to it. Equation (
16) determines the maximum number of principal components, and one can judge and act accordingly to provide enough snapshots if that number is low.
Snapshot data matrix, X, includes all state variable vectors for all Nsnt number of snapshots and can be expanded as
(17)
When the above matrix is built from all the available snapshots, the projection or transformation matrix is extracted from it which is the topic of the next section.
2.5. Singular Value Decomposition (SVD)
The transpose of the snapshot data matrix, , can be considered as a collection of vectors (Nsnt of them) in a full order N-dimensional space (N=Np×Ns). Any arbitrary unit vector in the reduced order Nsnt-dimensional space can be specified as
(18)
The left-hand side of the above equation is a vector in full space and can be written as a linear combination of unit vectors in this N-dimensional space. The above equation can be extended for all unit vectors in the reduced space resulting in
(19)
In the above equation, C is a coefficient matrix. Because both Ф and Ψ are unitary matrices and orthonormal in their own spaces, both sides cab be multiplied from right by ΨT to obtain
The above equation is the well-known form of the singular value decomposition formulation in which any matrix can be decomposed into two orthonormal matrices and one diagonal matrix. Therefore, the coefficient matrix is the same as the diagonal matrix in the singular value decomposition method shown with Σ in equation below.
There are many algorithms available for implementing SVD. Based on the matrix type, they are categorized into full SVD and truncated SVD acting on dense and sparse matrices, respectively. In this work, snapshot data matrices are dense matrices because there are many data points available for state variables and they are mainly non-zero. In terms of algorithms, SVD methods are categorized into QR decomposition based and Divide and Conquer based algorithms. Finally, in terms of available resources, libraries, and implementations, there are many libraries that are widely used by researchers and developers like Linear Algebra PACKage (LAPACK), Scalable Linear Algebra PACKage (ScaLAPACK), Parallel Linear Algebra Software for Multicore Architectures (PLASMA), Distributed Parallel Linear Algebra Software for Multicore Architectures (DPLASMA), Matrix Algebra on GPU and Multicore Architectures (MAGMA) and Software for Linear Algebra Targeting Exascale (SLATE) providing basic functionalities as well as addressing issues like bounded memory, parallelization and using GPU accelerators. In 2018, Dongara documented a comprehensive review of all SVD theories and algorithms and compared the performances of the above-mentioned libraries
| [3] | Dongarra, J, M Gate, and A Haidar. 2018. "The Singular Value Decomposition: Anatomy of Optimizing an Algorithm for Extreme Scale." SIAM review 60(4): 808-865.
https://doi.org/10.1137/17M1117732 |
[3]
. Going deeper through the singular value decomposition and its theory or implementation is out of the scope of this work, but it is proper to mention that the standard LAPACK implementation of the SVD is used in this work.
X
T in Equation (
21) can be considered as the snapshot data matrix written in its collective vector form. These vectors are now explained by three matrices in the right-hand side of this equation.
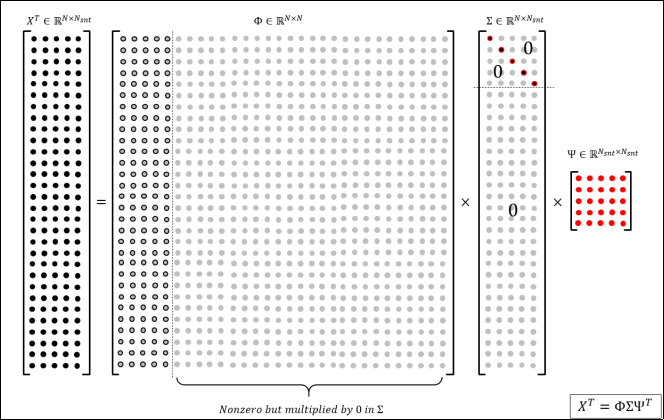
Figure 4, displays how these matrices are structured. Clearly, none of the unit vectors after N
sntth column in Ф plays any role in explaining X
T because they are all multiplied by zeros in Σ and are omitted. In addition, all first N
snt vectors in Ф have a corresponding coefficient on the main diagonal of Σ showing their weights in describing X
T. With this understanding it is time to define the reduced space.
Figure 4. A Schematic of Singular Value Decomposition and the Structure of Resulted Matrices.
2.6. Reduced Space Sizing
The process of finding a reduced space is an optimization process in which it is tried to reduce the error between a vector (state variable vector) and its projection to a minimum. Equation (
15) is the problem to solve to find the reduced space. Substituting X in Equation (
15) by X
T, which is the transpose of snapshot data matrix, gives
(22)
The above equation indicates that Ф, which was already found using SVD, is the basis for the reduced space. It is worth mentioning that out of all N available unit vectors in this matrix, there are only N
snt of them that are associated with nonzero eigenvalues. This is the fact that reduces the space dimension from N to the maximum of N
snt. This is consistent with the observation in
Figure 4. The importance of each first N
snt directions in Ф depends on its corresponding eigenvalue in Σ. Therefore, the unit vectors are usually sorted based on their corresponding eigenvalues and are added in that order to the reduced space until a certain level of energy preservation is reach based on
(23)
It was previously mentioned that one transformation matrix (Ф) is prepared for each state variable (x, y, ux, uy). Therefore, all the steps described in the above to find and size the reduced space should be repeated for each state variable starting with preparing Xx, Xy, Xux, Xuy and going through all steps to find Фx, Фy, Фux, Фuy.
2.7. Projection into Reduced Space
When all the transformation matrices are built using SVD, projecting the full space equations into the reduced space can be started. At this point governing equations are required to be multiplied by the transfer functions in order to project the equations in the reduced order space which has a smaller size and solve them there for reduced size state variable. Now, instead of full physics governing equations, nonintrusive equations developed by the author for any physics including particle-in-fluid flow is used to show how the combination can be used for a system with fixed number of particles, like the gas blower example, to decrease the computation time while maintaining an acceptable accuracy.
Based on Razavi’s nonintrusive theory, Equation (
24) can reproduce and predict the system behavior based on given runs or measurements for given inputs. In this equation
and
are called serial and parallel bridges and are simply gradients along and perpendicular to the closet available run trajectory in the full space.
is the input space vector and
represents the difference in input vectors between the closest run and a neighboring run. The rest of the equation is self-explanatory since it follows the simplest form of the Trajectory Piecewise Linearization (TPWL) proposed by Rewienski in 2003
| [16] | Rewienski, M, and J White. 2003. "A trajectory piecewise-linear approach to model order reduction and fast simulation of nonlinear circuits and micromachined devices." IEEE Transactions 22: 155-170.
https://10.1109/TCAD.2002.806601 |
[16]
.
is the projection of any point like
along the closet run trajectory and since most of the time the prediction run is close enough to the closest run, they are considered the same, but we keep the general form as
(24)
The projection matrix that was defined and sized in the previous subsection can transfer any state variable vector in the full space to its projection vector in the reduced space by
(25)
Where
is the reduced state variable vector and
is reduced space dimension. Substituting the above equation into Equation (
24) gives
(26)
Multiplying both sides from the left side by ФT gives
(27)
Defining the reduced serial and parallel bridges finalizes equations in the reduced space as:
(28)
Where
and
are reduced serial and parallel bridge matrices, respectively. Considering the size of parallel and serial bridges and all vectors in the above equation, the speed gain in calculations can be concluded by comparing it to Equation (
24). In the following section the implementation and speed gain will be discussed in further detail to see how much speed is expected to be gained from this nonintrusive model order reduction in terms of computation time.
2.8. Simulation Types
All state vectors and bridges in Equation (
28) exist in the reduced space except for the input vector. This vector is very small and there is no need to project it to the reduced space. Working with Equation (
28) in its current form requires projecting all vectors into reduced space and storing them for any calculation during the simulation process. This memory consumption is avoided by projecting vectors on the fly and transferring them when they are needed for a calculation. Serial and parallel bridges, on the other hand, are projected and stored in memory because transferring them on the fly many times is computationally expensive especially for the serial bridge that has a considerable size. Applying this implementation technique to Equation (
28) will change its form to
(29)
Clearly in the above equation, it is tried to avoid using full order serial bridge and the reduced one is used instead. This may not be the case for the parallel bridge since it is not as huge as the serial bridge is. For that reason, another version of the above equation is presented as
(30)
Based on the presented equations (Equation (
28), Equation (
29) and Equation (
30)) for the simulation runs, the simulation process is categorized into three types:
NIM – NIM: This is when the process is simulated based on Equation (
28) in which both serial and parallel bridges are calculated using the nonintrusive approach. This simulation happens completely in the full order space and none of the vectors or matrices are projected or stored in the reduced space.
ROM – NIM: This type of simulation is based on Equation (
29) in which serial bridges are transferred and stored in the reduced space, but parallel bridges remain in the full order space. None of the state vectors are projected for the reason discussed before.
ROM – ROM: When Equation (
30) is used for the simulation in which both serial and parallel bridges are transferred into the reduced space, it is the ROM – ROM case. Again, it is only bridges that are stored in their reduced formats and none of the state variable vectors are stored in the reduced space.
2.9. Speed Gain Discussion
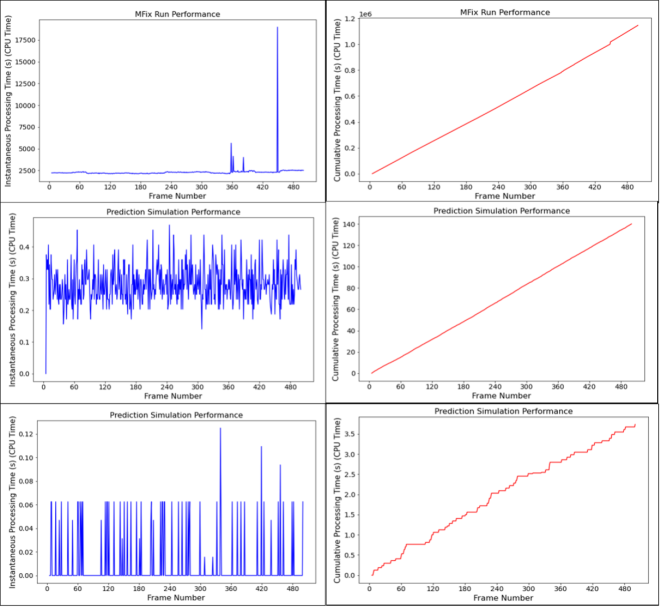
Simulation types were discussed in the above and now the speed gain from each type is reviewed and calculated. It was already shown by the author that using the nonintrusive approach instead of solving full order model and governing equations helps in gaining computation time. Here, the extra speed gain is calculated when model order reduction is added to the nonintrusive approach. Therefore, benchmarking will be against the NIM – NIM simulation process not against the full order solver. The practical speed gain from actual CPU times will be discussed and presented in the results section. What is discussed here is the expected theoretical speed gain relative to the NIM – NIM simulation when the model order reduction is added to it.
All presented simulation formulations are linear algebraic equations with matrix and vector multiplications. A simple approach was taken to calculate the number of operations required for a matrix – matrix or matrix – vector multiplication and it is extended to calculate the number of operations required for a single time step in a simulation process. Then, the results will be compared to see how much speed gain is expected from each simulation type against the NIM – NIM type. To start, it is assumed to have a general matrix (M), and a vector (b). The required order of operations for a matrix – vector multiplication is
(31)
Using Equation (
31), terms and operations in simulation type equations are broken into pieces and the required order of operations is calculated for each simulation type equation.
Table 2 to
Table 4 summarize the calculation steps and order of operations.
Table 2. Required Order of Operations for NIM – NIM Simulation Type.
NIM-NIM Simulation Type |
|
Step | Operation | Size | Order |
1. | | | |
2. | | | |
3. | | | |
4. | | | |
5. | | | |
Total= | |
Table 3. Required order of operations for ROM – NIM simulation type.
ROM-NIM Simulation Type |
|
Step | Operation | Size | Order |
1. | | | |
2. | | | |
3. | | | |
4. | | | |
5. | | | |
6. | | | |
7. | | | |
Total= | |
Table 4. Required order of operations for ROM-ROM simulation type.
ROM-ROM Simulation Type |
|
Step | Operation | Size | Order |
1. | | | |
2. | | | |
3. | | | |
4. | | | |
5. | | | |
6. | | | |
7. | | | |
8. | | | |
Total= | |
Comparing the operation orders against the NIM-NIM simulation gives
(32)
Usually the full space dimension, N, is 2 to 3 orders of magnitude bigger than the reduced space dimension, R. So, it is expected to see a significant acceleration in calculations from NIM – NIM type to ROM – NIM/ROM – ROM type. The above equation shows that NIM – ROM is faster than ROM – ROM but not significantly, therefore, ROM – ROM simulation type will be used in future benchmarking.