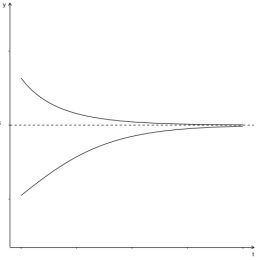
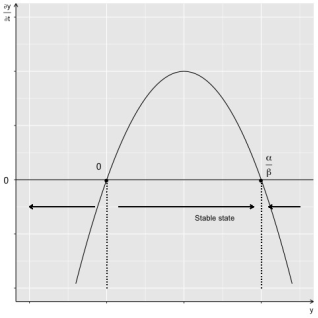
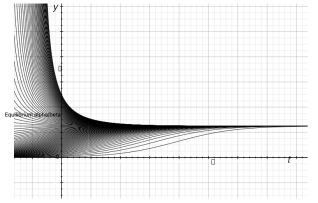
In academic research, bias refers to a type of systematic error that can distort measurements and/or affect investigations and their results. Biases can be present in both quantitative and qualitative research. The common effect of biases is undermining the power of statistical tests, therefore findings induced to support H0 hypothesis. Corrections depend on nature of bias and aimed to recover magnitude of association. Corrections use analytical constructs therefore applied in data analysis stage. Considered in the paper is of novel type and tentatively named inertia bias. This bias is of directed uncertainty about true value of index. One can find it in the range of designs and measures. The essence is the exposure takes time to shift index to new equilibrium. The problem is that researcher usually unaware of time required for index to settle down at new equilibrium. Therefore one inevitably measures the transition states instead of equilibrium yielding different magnitudes of attenuated association. How to obtain measure equilibrium value is the focus of the paper. Given the dynamical setup I referred to first order nonlinear differential equations, in particular logistic differential equation that meats necessary prerequisites: it should be separable equation, it has to have stable state, solutions have to descend or ascend toward equilibrium with the tangency in time. This paper describes range of circumstances where researcher faces the problem along with suggested solution, calculus, and tested software.
| Published in | American Journal of Health Research (Volume 12, Issue 6) |
| DOI | 10.11648/j.ajhr.20241206.14 |
| Page(s) | 186-192 |
| Creative Commons |
This is an Open Access article, distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution and reproduction in any medium or format, provided the original work is properly cited. |
| Copyright |
Copyright © The Author(s), 2024. Published by Science Publishing Group |
Bias, Equilibrium, Stable State, Logistic Differential Equation
Initial 10,10 | Example 1 (4) | Example 2 (5) | ||||
|---|---|---|---|---|---|---|
Solvers | alpha | beta | Equilibrium | alpha | beta | Equilibrium |
rootSolve | 2.000096 | 1.000066 | 1.999964 | 2.000096 | 1.000066 | 1.999964 |
rootSolve_J | 2.000096 | 1.000066 | 1.999964 | 2.000096 | 1.000066 | 1.999964 |
nleqslv | 1.9999722 | 0.9999848 | 2.000003 | 2.000001 | 1 | 2 |
optim | 12.950431 | 6.952232 | 1.862773 | 13.455259 | 6.569881 | 2.048022 |
nlm | 1.9999832 | 0.9999912 | 2.000001 | 13.189039 | 6.439741 | 2.04807 |
Initial 10,2 | Example 1 (4) | Example 2 (5) | ||||
|---|---|---|---|---|---|---|
Solvers | alpha | beta | Equilibrium | alpha | beta | Equilibrium |
rootSolve | 2.000096 | 1.000066 | 1.999964 | 2.000096 | 1.000066 | 1.999964 |
rootSolve_J | 2.000096 | 1.000066 | 1.999964 | 2.000096 | 1.000066 | 1.999964 |
nleqslv | 1.9999722 | 0.9999848 | 2.000003 | 2.000001 | 1 | 2 |
optim | 2.001468 | 1.000773 | 1.999922 | 2.002238 | 1.001078 | 2.000082 |
nlm | 48.97191 | 26.28929 | 1.862809 | 48.75963 | 23.80760 | 2.04807 |
Initial 1,2 | Example 1 (4) | Example 2 (5) | ||||
|---|---|---|---|---|---|---|
Solvers | alpha | beta | Equilibrium | alpha | beta | Equilibrium |
rootSolve | 2.000096 | 1.000066 | 1.999964 | 2.000096 | 1.000066 | 1.999964 |
rootSolve_J | 2.000096 | 1.000066 | 1.999964 | 2.000096 | 1.000066 | 1.999964 |
nleqslv | 1.9999722 | 0.9999848 | 2.000003 | 0 | 3.9226e-21 | 0 |
optim | 2.001468 | 1.000773 | 1.999922 | 1.9990474 | 0.9995273 | 1.999993 |
nlm | 48.97191 | 26.28929 | 1.862809 | 2.000006 | 1.000003 | 2 |
| [1] | Popovic A., Huecker, M. Study Bias. In: StatPearls [Internet]. Treasure Island (FL): StatPearls Publishing; 2024. PMID: 34662027 Bookshelf ID: NBK574513. |
| [2] | Florczak, K. Best Available Evidence or Truth for the Moment: Bias in Research. //Nursing Science Quarterly. Volume 35 Issue 1, 2022, pp. 20–24. |
| [3] | Arias, F., Navarro, M., Elfanagely, Y. Elfanagely, O. Biases in research studies. In: Handbook for Designing and Conducting Clinical and Translational Research, 2023, Ch. 31, pp. 191-194. |
| [4] | Odonnat, A., Feofanov, V., Redko, I. Leveraging Ensemble Diversity for Robust Self-Training in the Presence of Sample Selection Bias./ 27th International Conference on Artificial Intelligence and Statistics, AISTATS 2024; Valencia; Spain; 2-4 May 2024. In: Proceedings of Machine Learning Research. Vol. 238, 2024, pp. 595-603. |
| [5] | Jabarov, J. Bias in scientific research: How to identify and eliminate it. Journal of Science and Innovative Technologies International Scientific Research Journal. Issue 25, 2023, pp. 80-96. |
| [6] | Zheng, B. Ordinary Differential Equation and Its Application. In: Highlights in Science, Engineering and Technology. Vol. 72, 2023, pp. 645-65. |
| [7] | Henner, V., Nepomnyashchy, A., Belozerova, T. Ordinary Differential Equations: Analytical Methods and Applications. Springer, 2023, p.608. |
| [8] | Magnus, R. Essential Ordinary Differential Equations. Springer, 2023, p.283. |
| [9] | Simundi, A-M. Bias in research. Biochemia Medica. 2013 23(1): 12-15. |
| [10] | Smith, J., Noble, H. (2014). Bias in research. Evidence-Based Nursing, 17(4), 100-101. |
| [11] | Hunter, J., Schmidt, F. Methods of Meta-Analysis Corrected Error and Bias in Research Findings. Journal of the American Statistical Association. Vol. 86, No. 413(Mar., 1991), pp. 242-244 |
| [12] | Ornish, D., Scherwitz, L.W., Billings, J.H., Brown S.E., Gould, K. L., Merritt, T.A., Sparler, S., Armstrong, W. T., Ports, T. A., Kirkeeide, R.L., Hogeboom, C., Brand, R.J. Intensive lifestyle changes for reversal of coronary heart disease. JAMA. 1998 Dec 16; 280(23): 2001-7. |
| [13] | Smith, N., Smith, V. and Verner, M. (2006), "Do women in top management affect firm performance?A panel study of 2,500 Danish firms", International Journal of Productivity and Performance Management, Vol. 55 No. 7, pp. 569-593. |
| [14] | The R Project for Statistical Computing. |
| [15] | Aitkin, M., Francis, B., Hinde,J., Darnell, R. (2023). Statistical Modelling in R. Oxford University Press, 553. |
| [16] | Hasselman,B. (2003) Package ‘nleqslv’. |
| [17] |
Karline Soetaert, K., Hindmarsh, A., Eisenstat, S. C., et.al. (2003). Package ‘rootSolve’.
https://cran.r-project.org/web/packages/rootSolve/rootSolve.pdf |
| [18] |
R Core Team. (2024). Package «stats».
https://stat.ethz.ch/R-manual/R-devel/library/stats/html/00Index.html |
APA Style
Ocheredko, O. (2024). Phenomena of Inertia Bias in Research, Practicalities of Possible Adjustment. American Journal of Health Research, 12(6), 186-192. https://doi.org/10.11648/j.ajhr.20241206.14
ACS Style
Ocheredko, O. Phenomena of Inertia Bias in Research, Practicalities of Possible Adjustment. Am. J. Health Res. 2024, 12(6), 186-192. doi: 10.11648/j.ajhr.20241206.14
AMA Style
Ocheredko O. Phenomena of Inertia Bias in Research, Practicalities of Possible Adjustment. Am J Health Res. 2024;12(6):186-192. doi: 10.11648/j.ajhr.20241206.14
@article{10.11648/j.ajhr.20241206.14,
author = {Oleksandr Ocheredko},
title = {Phenomena of Inertia Bias in Research, Practicalities of Possible Adjustment
},
journal = {American Journal of Health Research},
volume = {12},
number = {6},
pages = {186-192},
doi = {10.11648/j.ajhr.20241206.14},
url = {https://doi.org/10.11648/j.ajhr.20241206.14},
eprint = {https://article.sciencepublishinggroup.com/pdf/10.11648.j.ajhr.20241206.14},
abstract = {In academic research, bias refers to a type of systematic error that can distort measurements and/or affect investigations and their results. Biases can be present in both quantitative and qualitative research. The common effect of biases is undermining the power of statistical tests, therefore findings induced to support H0 hypothesis. Corrections depend on nature of bias and aimed to recover magnitude of association. Corrections use analytical constructs therefore applied in data analysis stage. Considered in the paper is of novel type and tentatively named inertia bias. This bias is of directed uncertainty about true value of index. One can find it in the range of designs and measures. The essence is the exposure takes time to shift index to new equilibrium. The problem is that researcher usually unaware of time required for index to settle down at new equilibrium. Therefore one inevitably measures the transition states instead of equilibrium yielding different magnitudes of attenuated association. How to obtain measure equilibrium value is the focus of the paper. Given the dynamical setup I referred to first order nonlinear differential equations, in particular logistic differential equation that meats necessary prerequisites: it should be separable equation, it has to have stable state, solutions have to descend or ascend toward equilibrium with the tangency in time. This paper describes range of circumstances where researcher faces the problem along with suggested solution, calculus, and tested software.
},
year = {2024}
}
TY - JOUR T1 - Phenomena of Inertia Bias in Research, Practicalities of Possible Adjustment AU - Oleksandr Ocheredko Y1 - 2024/11/21 PY - 2024 N1 - https://doi.org/10.11648/j.ajhr.20241206.14 DO - 10.11648/j.ajhr.20241206.14 T2 - American Journal of Health Research JF - American Journal of Health Research JO - American Journal of Health Research SP - 186 EP - 192 PB - Science Publishing Group SN - 2330-8796 UR - https://doi.org/10.11648/j.ajhr.20241206.14 AB - In academic research, bias refers to a type of systematic error that can distort measurements and/or affect investigations and their results. Biases can be present in both quantitative and qualitative research. The common effect of biases is undermining the power of statistical tests, therefore findings induced to support H0 hypothesis. Corrections depend on nature of bias and aimed to recover magnitude of association. Corrections use analytical constructs therefore applied in data analysis stage. Considered in the paper is of novel type and tentatively named inertia bias. This bias is of directed uncertainty about true value of index. One can find it in the range of designs and measures. The essence is the exposure takes time to shift index to new equilibrium. The problem is that researcher usually unaware of time required for index to settle down at new equilibrium. Therefore one inevitably measures the transition states instead of equilibrium yielding different magnitudes of attenuated association. How to obtain measure equilibrium value is the focus of the paper. Given the dynamical setup I referred to first order nonlinear differential equations, in particular logistic differential equation that meats necessary prerequisites: it should be separable equation, it has to have stable state, solutions have to descend or ascend toward equilibrium with the tangency in time. This paper describes range of circumstances where researcher faces the problem along with suggested solution, calculus, and tested software. VL - 12 IS - 6 ER -
Social Medicine and Health Services Administration Department, Vinnytsia National Pirogov Medical University, Vinnytsia, Ukraine
Biography: Oleksandr Ocheredko is a chair of Social Medicine and Health Services Administration Department at National Pirogov Memorial Medical University, Vinnytsya, Ukraine. He completed his PhD in Social Medicine and Health Services Administration from Bogomolets National Medical University in 1995, and obtained full Doctorate of Medical Science in 2004. Was invited lecturer in Public Health School at Iowa State University in 2005. Since 2007 he is honoured with national professor degree. He is ISDSA member, maintainer of R package «ltable», currently serves on the Editorial Boards of Journal of Behavioral Data Science, US, as well as 4 Editorial Boards of national journals.
Research Fields: (1) Optimisation approach in Social Medicine and Health Services, (2) Data Science and Analytics in particular Power Analysis, Equilibrium Exploration, (3) Health Economics & Econometrics in particular applied economic analyses in Health Research, (4) Evidence based Clinical Medicine and Evidence based Public Health in particular meta-analysis, (5) MCMC algorithms, in particular stationarity detection.
Information