Image semantic segmentation is essential in fields such as computer vision, autonomous driving, and human-computer interaction due to its ability to accurately identify and classify each pixel in an image. However, this task is fraught with challenges, including the difficulty of obtaining detailed pixel labels and the problem of class imbalance in segmentation datasets. These challenges can hinder the effectiveness and efficiency of segmentation models. To address these issues, we propose an active learning semantic segmentation model named CG_D3QN, which is designed and implemented based on an enhanced Double Deep Q-Network (D3QN). The proposed CG_D3QN model incorporates a hybrid network structure that combines a dueling network architecture with Gated Recurrent Units (GRUs). This novel approach improves policy evaluation accuracy and computational efficiency by mitigating a Q-value overestimation and making better use of historical state information. Our experiments, conducted on the CamVid and Cityscapes datasets, reveal that the CG_D3QN model significantly reduces the number of required sample annotations by 65.0% compared to traditional methods. Additionally, it enhances the mean Intersection over Union (IoU) for underrepresented categories by approximately 1% to 3%. These results highlight the model’s effectiveness in lowering annotation costs, addressing class imbalance, and its versatility across different segmentation networks.
| Published in | International Journal on Data Science and Technology (Volume 10, Issue 3) |
| DOI | 10.11648/j.ijdst.20241003.12 |
| Page(s) | 51-61 |
| Creative Commons |
This is an Open Access article, distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution and reproduction in any medium or format, provided the original work is properly cited. |
| Copyright |
Copyright © The Author(s), 2024. Published by Science Publishing Group |
Deep Reinforcement Learning, Active Learning, Image Semantic Segmentation, Dueling Network, Gated Recurrent Unit (GRU)
Dataset | CamVid | Cityscapes |
|---|---|---|
the state subset | 10 | 10 |
The training subset | 100 | 150 |
The evaluation subset | 260 | 2615 |
The reward subset | 104 | 200 |
Hyperparameters | CamVid | Cityscapes |
|---|---|---|
Region_size | 80*90 | 128*128 |
Al_algorithm | / | / |
Rl_episodes | 100 | 100 |
Rl_buffer | 600 | 1000 |
lr | 0.001 | 0.0001 |
gamma | 0.998 | 0.998 |
Train_batch_size | 32 | 16 |
Val_batch_size | 4 | 1 |
patience | 10 | 10 |
Num_each_iter | 24 | 256 |
R1_pool | 10 | 10 |
Method | Road | SideWalk | Building | Wall | Fence | Pole | Traffic Light |
|---|---|---|---|---|---|---|---|
Bald | 96.320.03 | 74.740.15 | 89.770.06 | 42.280.17 | 46.910.20 | 49.440.17 | 52.510.28 |
Random | 93.940.06 | 65.130.22 | 88.280.11 | 37.700.47 | 44.810.43 | 45.700.23 | 48.860.39 |
Ralis | 95.740.06 | 73.130.25 | 89.170.10 | 43.610.30 | 48.010.28 | 47.330.17 | 50.050.29 |
CG_D3QN | 96.990.03 | 77.550.14 | 90.850.06 | 45.580.12 | 50.030.14 | 52.180.13 | 56.530.23 |
Traffic Sign | Vegetation | Terrain | Sky | Person | Rider | Car | |
|---|---|---|---|---|---|---|---|
Bald | 59.560.22 | 89.310.05 | 59.080.12 | 92.640.05 | 73.010.10 | 32.460.34 | 91.520.06 |
Random | 55.470.39 | 87.920.10 | 54.580.29 | 91.730.17 | 69.700.17 | 28.980.51 | 88.820.12 |
Ralis | 57.980.26 | 88.630.08 | 57.260.17 | 90.180.18 | 92.960.17 | 33.410.52 | 91.110.12 |
CG_D3QN | 64.220.19 | 89.840.05 | 59.600.07 | 93.450.04 | 74.960.08 | 41.540.03 | 92.760.05 |
Truck | Bus | Train | Motorcycle | Bicycle | |
|---|---|---|---|---|---|
Bald | 30.290.40 | 27.130.29 | 38.400.51 | 37.290.39 | 61.080.21 |
Random | 21.290.66 | 23.660.69 | 37.550.89 | 25.990.67 | 57.380.42 |
Ralis | 36.980.73 | 35.430.61 | 54.260.77 | 34.240.39 | 61.300.30 |
CG_D3QN | 38.430.29 | 35.940.22 | 54.190.33 | 44.320.27 | 64.970.18 |
Mthod | Accuracy | MIoU |
|---|---|---|
DDRNet | 75.99 | 34.76 |
CG_D3NQ+DDRNet | 75.71 | 35.92 |
BiSeNet | 77.46 | 34.08 |
CG_D3NQ+ BiSeNet | 82.41 | 38.61 |
| [1] | Csurka G, Volpi R, Chidlovskii B. Semantic image segmentation: Two decades of research [J]. Foundations and Trends® in Computer Graphics and Vision, 2022, 14 (1-2): 1-162. |
| [2] | Liao Wensen, Xu Cheng, Liu Hongzhe, et al. Real-time semantic segmentation method for road scenes based on multi-branch networks [J]. Computer Applications Research, 2023, 40 (8): 2526-2530. |
| [3] | Shu Xiu, Yang Yunyun, Xie Ruicheng, et al. Als: Active Learning-Based Image Segmentation Model for Skin Lesion [J/OL]. SSRN Electronic Journal, 2022. (2022-06-21) [2024-02-05]. |
| [4] | Zhang Meng, Han Bing, Wang Zhe, et al. Thyroid Cancer Pathological Image Classification Method Based on Deep Active Learning [J]. Journal of Nanjing University: Natural Sciences, 2021. 57 (1): 21-28. |
| [5] | Liu Xiaoyu, Zuo Jie, Sun Pinjie. Research Progress of Machine Learning Algorithms Based on Active Learning [J]. Modern Computer, 2021 (3): 32-36. |
| [6] | Siméoni O, Budnik M, Avrithis Y, et al. Rethinking deep active learning: Using unlabeled data at model training [C] // Proc of the 25th International conference on pattern recognition. NJ: IEEE Press, 2021: 1220-1227. |
| [7] | Konyushkova K, Sznitman R, Fua P. Learning Active Learning from Data [J]. Advances in neural information processing systems, 2017, 30. |
| [8] | Ren Pengzhen, Xiao Yun, Chang Xiaojun, et al. A Survey of Deep Active Learning [J]. ACM Computing Surveys, 2022: 1-40. |
| [9] | Budd S, Robinson E C, Kainz B. A survey on active learning and humanin-the-loop deep learning for medical image analysis [J]. Medical Image Analysis, 2021: 102062. |
| [10] | Hu Zeyu, Bai Xuyang, Zhang Runze, et al. LiDAL: Inter-frame Uncertainty Based Active Learning for 3D LiDAR Semantic Segmentation [C] // Proc of European Conference on Computer Vision. Cham: Springer, 2022: 248-265. |
| [11] | Wiering M A, Van Otterlo M. Reinforcement learning [J]. Adaptation, learning, and optimization, 2012, 12 (3): 729. |
| [12] | Fan Yingying, Zhang Shanshan. Hyperspectral Remote Sensing Image Classification Method Based on Deep Active Learning [J]. Journal of Northeast Normal University: Natural Sciences Edition, 2022, 54 (4): 64-70. |
| [13] | Cai L, Xu X, Liew J H, et al. Revisiting superpixels for active learning in semantic segmentation with realistic annotation costs [C] // Proc of the IEEE/CVF conference on computer vision and pattern recognition. NJ: IEEE Press, 2021: 10988-10997. |
| [14] | Mackowiak R, Lenz P, Ghori O, et al. CEREALS-Cost-Effective REgion-based Active Learning for Semantic Segmentation [J/OL]. British Machine Vision Conference, 2018. (2018-10-23) [2024-02-05]. |
| [15] | Gal Y, Islam R, Ghahramani Z. Deep Bayesian Active Learning with Image Data [C] // International conference on machine learning. New York: PMLR, 2017: 1183-1192. |
| [16] | Hu Mingzhe, Zhang Jiahan, Matkovic L, et al. Reinforcement Learning in Medical Image Analysis: Concepts, Applications, Challenges, and Future Directions [J]. Journal of Applied Clinical Medical Physics, 2023, 24 (2): e13898. |
| [17] | Zhou Wenhong, Li Jie, Zhang Qingjie. Joint Communication and Action Learning in Multi-Target Tracking of UAV Swarms with Deep Reinforcement Learning [J]. Drones, 2022, 6 (11): 339. |
| [18] | Sener O, Savarese S. Active Learning for Convolutional Neural Networks: A Core-Set Approach [EB/OL]. (2018-06-01) [2024-02-05]. |
| [19] | Dhiman G, Kumar A V, Nirmalan R, et al. Multi-modal active learning with deep reinforcement learning for target feature extraction in multimedia image processing applications [J]. Multimedia Tools and Applications, 2023, 82 (4): 5343-5367. |
| [20] | Chan R, Rottmann M, Hyuger F, et al. Application of Decision Rules for Handling Class Imbalance in Semantic Segmentation [EB/OL]. (2019-01-24) [2024-02-05]. |
| [21] | Casanova A, Pinheiro Pedro O, Rostamzadeh N, et al. Reinforced active learning for image segmentation [J/OL]. International Conference on Learning Representations, 2020. (2020-02-16) [2024-02-05]. |
| [22] | Wang Ziyu, Schaul T, Hessel M, et al. Dueling Network Architectures for Deep Reinforcement Learning [C] // International conference on machine learning. New York: PMLR, 2016: 1995-2003. |
| [23] | Huang Guoyang, Li Xinyi, Zhang Bing, et al. PM2. 5 concentration forecasting at surface monitoring sites using GRU neural network based on empirical mode decomposition [J]. Science of the Total Environment, 2021, 768: 144516. |
| [24] | Lin T Y, Dollár P, Girshick R, et al. Feature pyramid networks for object detection [C] // Proc of the IEEE conference on computer vision and pattern recognition. NJ: IEEE Press, 2017: 2117-2125. |
| [25] | Pan Huihui, Hong Yuanduo, Sun Weichao, et al. Deep Dual-Resolution Networks for Real-Time and Accurate Semantic Segmentation of Traffic Scenes [J]. IEEE Trans on Intelligent Transportation Systems, 2022, 24 (3): 3448-3460. |
| [26] | Yu Changqian, Wang Jingbo, Peng Chao, et al. Bisenet: Bilateral segmentation network for real-time semantic segmentation [C] // Proc of the European conference on computer vision. Berlin: Springer, 2018: 325-341. |
APA Style
Yu, Y. (2024). An Active Learning Semantic Segmentation Model Based on an Improved Double Deep Q-Network. International Journal on Data Science and Technology, 10(3), 51-61. https://doi.org/10.11648/j.ijdst.20241003.12
ACS Style
Yu, Y. An Active Learning Semantic Segmentation Model Based on an Improved Double Deep Q-Network. Int. J. Data Sci. Technol. 2024, 10(3), 51-61. doi: 10.11648/j.ijdst.20241003.12
AMA Style
Yu Y. An Active Learning Semantic Segmentation Model Based on an Improved Double Deep Q-Network. Int J Data Sci Technol. 2024;10(3):51-61. doi: 10.11648/j.ijdst.20241003.12
@article{10.11648/j.ijdst.20241003.12,
author = {Yan Yu},
title = {An Active Learning Semantic Segmentation Model Based on an Improved Double Deep Q-Network
},
journal = {International Journal on Data Science and Technology},
volume = {10},
number = {3},
pages = {51-61},
doi = {10.11648/j.ijdst.20241003.12},
url = {https://doi.org/10.11648/j.ijdst.20241003.12},
eprint = {https://article.sciencepublishinggroup.com/pdf/10.11648.j.ijdst.20241003.12},
abstract = {Image semantic segmentation is essential in fields such as computer vision, autonomous driving, and human-computer interaction due to its ability to accurately identify and classify each pixel in an image. However, this task is fraught with challenges, including the difficulty of obtaining detailed pixel labels and the problem of class imbalance in segmentation datasets. These challenges can hinder the effectiveness and efficiency of segmentation models. To address these issues, we propose an active learning semantic segmentation model named CG_D3QN, which is designed and implemented based on an enhanced Double Deep Q-Network (D3QN). The proposed CG_D3QN model incorporates a hybrid network structure that combines a dueling network architecture with Gated Recurrent Units (GRUs). This novel approach improves policy evaluation accuracy and computational efficiency by mitigating a Q-value overestimation and making better use of historical state information. Our experiments, conducted on the CamVid and Cityscapes datasets, reveal that the CG_D3QN model significantly reduces the number of required sample annotations by 65.0% compared to traditional methods. Additionally, it enhances the mean Intersection over Union (IoU) for underrepresented categories by approximately 1% to 3%. These results highlight the model’s effectiveness in lowering annotation costs, addressing class imbalance, and its versatility across different segmentation networks.
},
year = {2024}
}
TY - JOUR T1 - An Active Learning Semantic Segmentation Model Based on an Improved Double Deep Q-Network AU - Yan Yu Y1 - 2024/08/27 PY - 2024 N1 - https://doi.org/10.11648/j.ijdst.20241003.12 DO - 10.11648/j.ijdst.20241003.12 T2 - International Journal on Data Science and Technology JF - International Journal on Data Science and Technology JO - International Journal on Data Science and Technology SP - 51 EP - 61 PB - Science Publishing Group SN - 2472-2235 UR - https://doi.org/10.11648/j.ijdst.20241003.12 AB - Image semantic segmentation is essential in fields such as computer vision, autonomous driving, and human-computer interaction due to its ability to accurately identify and classify each pixel in an image. However, this task is fraught with challenges, including the difficulty of obtaining detailed pixel labels and the problem of class imbalance in segmentation datasets. These challenges can hinder the effectiveness and efficiency of segmentation models. To address these issues, we propose an active learning semantic segmentation model named CG_D3QN, which is designed and implemented based on an enhanced Double Deep Q-Network (D3QN). The proposed CG_D3QN model incorporates a hybrid network structure that combines a dueling network architecture with Gated Recurrent Units (GRUs). This novel approach improves policy evaluation accuracy and computational efficiency by mitigating a Q-value overestimation and making better use of historical state information. Our experiments, conducted on the CamVid and Cityscapes datasets, reveal that the CG_D3QN model significantly reduces the number of required sample annotations by 65.0% compared to traditional methods. Additionally, it enhances the mean Intersection over Union (IoU) for underrepresented categories by approximately 1% to 3%. These results highlight the model’s effectiveness in lowering annotation costs, addressing class imbalance, and its versatility across different segmentation networks. VL - 10 IS - 3 ER -
North China University of Technology, Brunel London School, Beijing, China
Biography: Yan Yu is an undergraduate student at Brunel London School, North China University of Technology, majoring in Data Science and Big Data Technology. Her primary research interests include graphical processing and unsupervised one-point attacks based on differential evolution. As the first author, he has published an EI-indexed conference paper that introduced an unsupervised adversarial attack method for detecting security vulnerabilities in critical network domains. Currently, Yan is working on an innovative evolutionary algorithm that leverages overlapping route information to accelerate the optimization of Vehicle Routing Problems (VRP) and Discrete Split Delivery Problems (DSDVRP). This work is under review in an EI-indexed journal. Additionally, Yan leads a municipal-level innovation and entrepreneurship project focused on applying image semantic segmentation methods to high-resolution remote sensing imagery, where he has achieved significant progress.
Research Fields: Graphical processing, unsupervised one-point attacks, image semantic segmentation

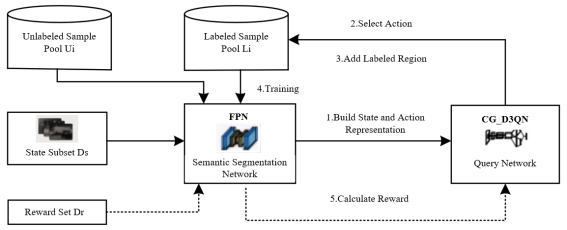
Figure 1. Active learning semantic segmentation workflow framework.
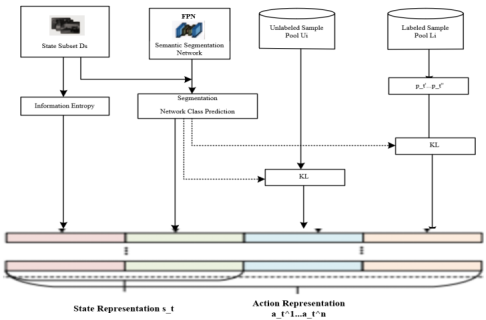
Figure 2. State representation and action representation.
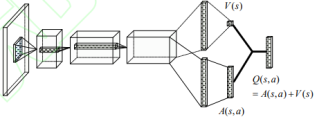
Figure 3. Dueling network structure.
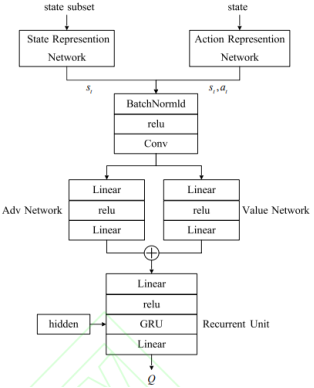
Figure 4. CG_D3QN network framework.
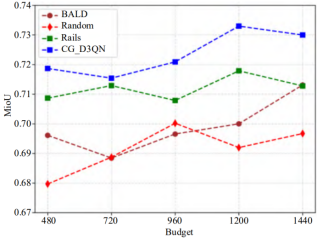
Figure 5. Comparison of experimental results for various algorithms on the Camvid dataset.
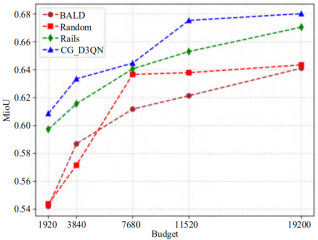
Figure 6. Comparison of experimental results for various algorithms on the Cityscapes dataset.

Figure 7. 9Visualization results on the Cityscapes dataset.
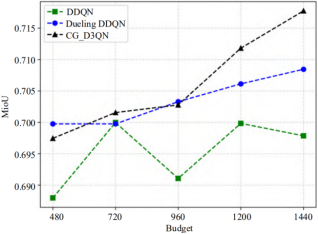
Figure 8. Ablation experiment results on the Camvid dataset.

Figure 9. Visualization results on the Camvid dataset.
Information

