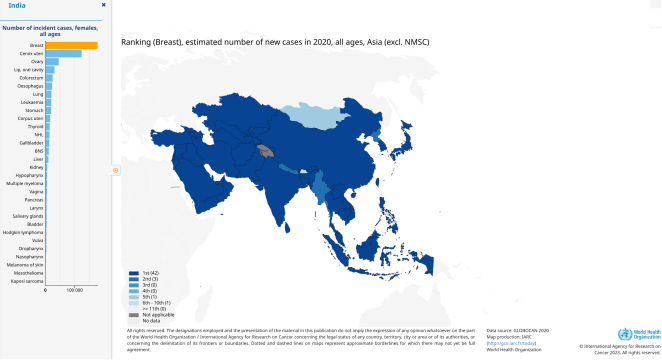
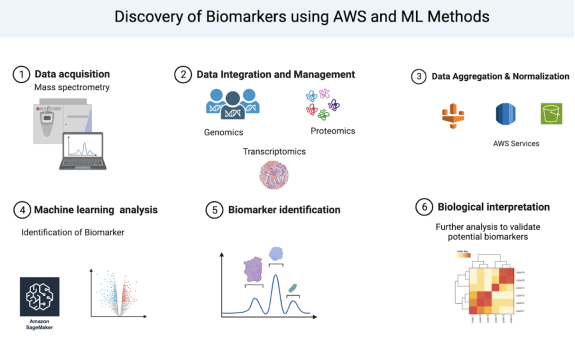
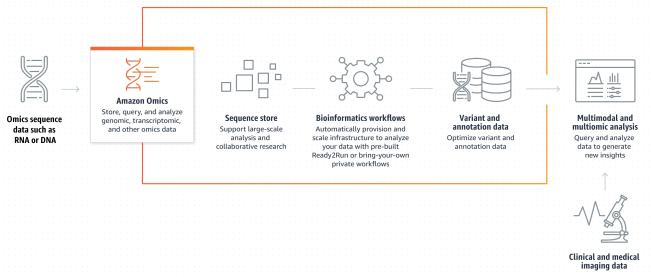
Breast cancer presents a profound global health challenge, compounded by unique intricacies within the Indian demographic, necessitating bespoke research methodologies. This abstract delineates the profound impact of Amazon Web Services (AWS) Cloud Solutions on advancing multi-omics breast cancer biomarker research, with a particular focus on Indian patient cohorts. It initiates with an exposition of the inherent challenges encountered during the transition from raw data acquisition to clinical diagnosis, emphasizing the indispensable role of cloud-based infrastructures in expediting this complex trajectory. Harnessing the comprehensive capabilities of AWS, this study elucidates how cloud solutions facilitate the seamless integration and analysis of multifaceted omics datasets, encompassing genomics, transcriptomics, proteomics, and metabolomics. Central to this endeavor is a meticulous exploration of region-specific molecular markers germane to breast cancer within the Indian populace, illuminating their diagnostic and therapeutic ramifications. By capitalizing on AWS Cloud's scalability and computational acumen, this research underscores notable efficiency enhancements in processing voluminous datasets and distilling salient patterns therein. Furthermore, the discourse extends to the broader ramifications of these technological advancements within the precision medicine landscape, emphasizing the potential for tailored therapeutic interventions. This research heralds a paradigmatic shift in the application of cloud-based infrastructures to unravel the intricate tapestry of breast cancer, transcending geographical confines. Through its provision of insights poised to augment diagnostic precision and therapeutic efficacy on a global scale, this study marks a seminal stride towards fully harnessing the potential of precision oncology in combating breast malignancies.
| Published in | Computational Biology and Bioinformatics (Volume 12, Issue 1) |
| DOI | 10.11648/j.cbb.20241201.11 |
| Page(s) | 1-11 |
| Creative Commons |
This is an Open Access article, distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution and reproduction in any medium or format, provided the original work is properly cited. |
| Copyright |
Copyright © The Author(s), 2024. Published by Science Publishing Group |
Biomarker, Breast Cancer, Multi-Omics, Amazon Web Services
Data source | Aspect | Description |
|---|---|---|
NCBI GenBank | Genomic Sequences | A comprehensive repository of publicly available nucleotide sequences, providing a vast collection for genomic studies. |
Ensembl | Genomic Annotations | Offers genome annotations, gene sequences, and functional information, facilitating the interpretation of genomic data. |
1000 Genomes Project | Genomic Variation | A global initiative cataloging human genetic variation, aiding in understanding population diversity and disease genetics. |
UCSC Genome Browser | Genomic Visualization | A user-friendly platform for visualizing and exploring genomic data, supporting researchers in data interpretation. |
dbSNP | Single Nucleotide Polymorphisms (SNPs) | A database of common and rare SNPs, assisting in the identification of genetic variations across populations. |
ClinVar | Clinical Genomics | Aggregates information on clinically relevant genomic variations, facilitating the interpretation of genetic variants in a clinical context. |
Genomic Data Commons (GDC) | Cancer Genomics | A resource providing access to genomic and clinical data from cancer studies, promoting collaborative research in cancer genomics. |
Encode | Functional Genomics | Focuses on functional elements in the genome, providing data on gene regulation, chromatin structure, and epigenetic modifications. |
RefSeq | Reference Genomes | A curated collection of reference sequences, serving as a benchmark for genomic analysis and annotation. |
HapMap | Population Genetics | A project mapping common genetic variations in human populations, aiding in the understanding of population genetics and disease susceptibility. |
Data sources | Aspect | Descriptions |
|---|---|---|
ENCODE (Encyclopedia of DNA Elements) | Genomic DNA Methylation | Comprehensive resource providing maps of DNA methylation patterns, aiding in understanding epigenetic regulation at a genome-wide level. |
Roadmap Epigenomics Project | Histone Modifications | Large-scale initiative mapping histone modifications across various cell types and tissues, facilitating the exploration of chromatin dynamics and gene regulation. |
GEO (Gene Expression Omnibus) | Epigenomic Data Sets | A public repository hosting a diverse range of epigenomic datasets, including ChIP-seq, bisulfite sequencing, and other assays, fostering data sharing and collaboration. |
Blueprint Epigenome Project | DNA Methylation and Histone Modifications | Focuses on profiling epigenetic marks across diverse human cell types, contributing valuable insights into the regulatory landscape of the human genome. |
UCSC Genome Browser | Epigenetic Annotations | Integrates epigenomic data with genomic annotations, allowing users to visualize and analyze epigenetic features in the context of the entire genome. |
NIH Epigenomics Data Analysis and Coordination Center (EDACC) | Data Coordination | Central hub for storing and distributing epigenomic data generated by various consortia, ensuring standardized formats and accessibility for researchers. |
BLUEPRINT Data Portal | DNA Methylation, Histone Modifications | Provides access to datasets generated by the BLUEPRINT project, offering insights into the epigenetic variation in different hematopoietic cell types. |
Cistrome Data Browser | Transcription Factor Binding | A platform hosting a collection of ChIP-seq datasets, facilitating the exploration of transcription factor binding sites and their regulatory roles. |
Epigenome Browser | Interactive Visualization | An online tool for exploring and visualizing epigenomic data, enabling researchers to interactively analyze and interpret epigenetic information. |
IHEC Data Portal | International Epigenome Consortium (IHEC) Data | Hosts data from the IHEC, promoting global collaboration and standardization in epigenomic data generation and analysis. |
Data sources | Aspect | Descriptions |
|---|---|---|
Microarray | Technology | Utilizes hybridization-based methods for transcript quantification, providing a snapshot of gene expression in a sample. |
RNA-Seq | Technology | Employs high-throughput sequencing to quantify RNA transcripts, allowing for accurate measurement and detection of novel transcripts. |
SAGE | Technology | Serial Analysis of Gene Expression provides a quantitative assessment of gene expression patterns by sequencing short tags. |
MPSS | Technology | Massively Parallel Signature Sequencing enables digital quantification of transcripts, providing a comprehensive view of the transcriptome. |
RNA-ISH | Technology | RNA In Situ Hybridization allows for the visualization and localization of specific RNA transcripts within cells and tissues. |
Databases | Resource | Publicly available databases such as NCBI Gene Expression Omnibus (GEO) and European Bioinformatics Institute (EBI) house vast transcriptomic datasets for diverse biological samples. |
Single-Cell RNA-Seq | Technology | Facilitates transcriptomic analysis at the single-cell level, enabling the study of cellular heterogeneity and identification of rare cell types. |
Long-Read Sequencing | Technology | Utilizes sequencing technologies with extended read lengths, providing a more comprehensive view of complex transcript structures and isoforms. |
Pathway Analysis Tools | Analysis Tool | Various tools like Gene Set Enrichment Analysis (GSEA) and Ingenuity Pathway Analysis (IPA) interpret transcriptomic data in the context of biological pathways, aiding in functional interpretation. |
Differential Expression Analysis Tools | Analysis Tool | Tools such as DESeq2 and edgeR identify genes showing significant expression changes between different experimental conditions, facilitating the discovery of key regulatory elements. |
Data Integration Platforms | Analysis Tool | Platforms like Seurat and Scanpy integrate transcriptomic data with other omics layers, enhancing the understanding of the interplay between genes, proteins, and metabolites in complex biological systems. |
Data sources | Aspect | Descriptions |
|---|---|---|
MassIVE | Data Repository | MassIVE is a community resource developed by the National Center for Integrative Proteomics (NCIP) to promote the global, free exchange of mass spectrometry data. |
ProteomeXchange | Data Exchange | ProteomeXchange serves as a comprehensive and centralized repository for proteomics data. It facilitates data sharing and retrieval across multiple proteomics repositories, promoting open data practices. |
PeptideAtlas | Protein Identification | PeptideAtlas is a repository that houses high-quality mass spectrometry-based shotgun proteomics data, providing a valuable resource for protein identification and quantification. |
Human Proteome Map | Protein Expression Atlas | The Human Proteome Map (HPM) project provides a comprehensive resource for understanding tissue-specific protein expression patterns, aiding in the exploration of the human proteome across various tissues. |
PRIDE (PRoteomics IDEntifications) | Dataset Archive | PRIDE is a database for storing and disseminating mass spectrometry-based proteomics data. It allows researchers to submit, browse, and download proteomics datasets, fostering data accessibility and reuse. |
MaxQB | Quantitative Proteomics | MaxQB is a database that specializes in quantitative information about the human proteome. It includes data on protein expression levels, modifications, and interactions, supporting research in quantitative proteomics. |
MassBank | Mass Spectrometry Data | MassBank is an open-access database that focuses on mass spectrometry data for small molecules, including metabolites and peptides. It provides a platform for sharing and retrieving mass spectra information. |
jPOST (Japan Proteome Standard Repository) | Proteome Standardization | jPOST is a repository dedicated to standardizing and archiving proteome data generated by Japanese researchers. It aims to enhance the quality and reproducibility of proteomics experiments through data sharing and standardization. |
iProX (Integrated Proteome Resources) | Integrated Proteomics | iProX serves as an integrated platform for storing and sharing proteomics data along with related multiomics data. It supports the integration of proteomics with genomics, transcriptomics, and other molecular datasets. |
PRIN (Proteomics Integrated) | Cross-Omics Integration | PRIN is a platform that integrates proteomics data with other omics data, enabling cross-omics analysis. It promotes a holistic understanding of biological systems by combining proteomics information with genomic, transcriptomic, and metabolomic data. |
Data sources | Aspect | Descriptions |
|---|---|---|
HMDB (Human Metabolome Database) | Comprehensive Metabolite Information | HMDB provides a vast collection of metabolite data, including chemical structures, spectral information, and biological roles, offering a comprehensive resource for metabolomics research. |
MetaboLights | Metabolomics Study Metadata | MetaboLights serves as a repository for metabolomics studies, housing metadata such as experimental protocols, sample information, and analytical data, facilitating data sharing and collaboration. |
MassBank | Mass Spectrometry Data | MassBank offers a repository of mass spectrometry data, including spectral information and metabolite identification, supporting metabolomics researchers in the annotation and validation of compounds. |
Lipid Maps | Lipid Metabolism Information | Lipid Maps focuses on lipid metabolism, providing a curated resource of lipid structures, pathways, and associated data, aiding in the exploration of lipidomics and its implications in health and disease. |
GNPS (Global Natural Products Social Molecular Networking) | Molecular Networking and Dereplication | GNPS facilitates the sharing and analysis of mass spectrometry data, enabling molecular networking for the identification of known and novel metabolites, contributing to metabolomics research and discovery. |
Metabolomics Workbench | Diverse Metabolomics Datasets | Metabolomics Workbench hosts a variety of metabolomics datasets, spanning different organisms and experimental conditions, offering researchers access to a broad range of data for comparative analyses and exploration. |
NMRShiftDB | Nuclear Magnetic Resonance (NMR) Data | NMRShiftDB compiles nuclear magnetic resonance (NMR) data for metabolites, including chemical shifts and coupling constants, supporting metabolomics investigations leveraging NMR spectroscopy techniques. |
KEGG (Kyoto Encyclopedia of Genes and Genomes) | Metabolic Pathways and Annotations | KEGG provides a comprehensive resource for metabolic pathways, offering annotated information on metabolites, enzymes, and their interactions, aiding in the contextualization of metabolomics data within biological pathways. |
Pros | Cons |
|---|---|
Scalability: Easily scale resources as needed for genomics projects. | Cost: Costs can accumulate quickly, and pricing can be complex. (ref) |
Security: Benefit from AWS's robust security features and compliance standards. | Learning Curve: It may take time to learn and configure the services. |
Data Management: Efficiently store, process, and manage large genomic datasets. | Connectivity: Reliance on an internet connection may lead to downtime. |
Flexibility: Choose from various AWS services tailored to genomics research. | Data Transfer: Uploading and downloading large datasets can be time-consuming. |
Integration: Easily integrate with other AWS services and third-party tools. | Compliance: Ensuring data compliance with regulatory standards can be complex. |
Collaboration: Eases collaboration among research teams and organizations. | Dependency: Your project's success may depend on AWS services. |
Automation: Streamline analysis and workflows with AWS automation tools. | Lock-In vendor: Migrating away from AWS can be challenging and costly. |
Analytics: Access advanced analytics and machine learning capabilities. | Support: The quality and responsiveness of support can vary. |
Disaster Recovery: Benefit from AWS's disaster recovery and backup solutions. | Data Privacy: Concerns may arise about data privacy and control. |
Global Reach: AWS has data centres worldwide, ensuring global accessibility. | Resource Limits: There may be resource limits that affect your projects. |
AWS | Amazon Web Services |
BAM | Binary Alignment Map |
BCSC | Breast Cancer Surveillance Consortium |
BMC | BioMed Central |
CA | Cancer |
CRAM | Compressed Read Archive in Minutes |
DB | Database |
DNA | Deoxyribonucleic Acid |
EBI | European Bioinformatics Institute |
EDACC | Early Detection Research Network Data Analysis Center |
ENCODE | Encyclopedia of DNA Elements |
FAIR | Findable, Accessible, Interoperable, Reusable |
FASTA | Fast-All Sequence Search Tool |
FASTQ | Fast Quality Control |
GAIT | Genome Analysis Information Tool |
GDC | Genomic Data Commons |
GEO | Gene Expression Omnibus |
GM | Genetically Modified |
GNPS | Global Natural Product Social Molecular Networking |
GSEA | Gene Set Enrichment Analysis |
HIPAA | Health Insurance Portability and Accountability Act |
HMDB | Human Metabolome Database |
HPM | Human Proteome Map |
HUL | Human Unidentified LncRNA |
HUMANA | Human Microbiome Analysis |
IDE | Integrated Development Environment |
IHEC | International Human Epigenome Consortium |
IP | Intellectual Property |
IPA | Ingenuity Pathway Analysis |
ISH | In Situ Hybridization |
IVE | Image Visualization Environment |
KEGG | Kyoto Encyclopedia of Genes and Genomes |
ML | Machine Learning |
MOBC | Methylated DNA Immunoprecipitation with Bisulfite Conversion |
MPSS | Massively Parallel Signature Sequencing |
MS | Mass Spectrometry |
NCBI | National Center for Biotechnology Information |
NCIP | National Cancer Informatics Program |
NGS | Next-Generation Sequencing |
NIH | National Institutes of Health |
NMR | Nuclear Magnetic Resonance |
NMRS | Nuclear Magnetic Resonance Spectroscopy |
PL | Pipeline |
POST | Power of Statistical Tests |
PR | Public Relations |
PRESS | Public Repository for Electronically Stored Sequences |
PRIDE | PRoteomics IDEntifications database |
PRIN | Pipeline of RNA-Sequencing |
QB | Quality Base |
RNA | Ribonucleic Acid |
SAGE | Serial Analysis of Gene Expression |
SNP | Single Nucleotide Polymorphism |
TM | Text Mining |
UCSC | University of California, Santa Cruz |
USA300 | United States of America 300 |
WDL | Workflow Description Language |
WHO | World Health Organization |
| [1] | A. N. Giaquinto et al., “Breast Cancer Statistics, 2022,” CA. Cancer J. Clin., vol. 72, no. 6, pp. 524–541, Nov. 2022, |
| [2] | A. Vikram Pawar, “CLASSIFICATION OF BREAST CANCER CELL LINES INTO SUBTYPES BASED ON GENETIC PROFILES,” 2015. |
| [3] | F. Tian, Y. Wang, M. Seiler, and Z. Hu, “Functional characterization of breast cancer using pathway profiles,” BMC Med. Genomics, vol. 7, no. 1, Jul. 2014, |
| [4] | K. Sathishkumar, M. Chaturvedi, P. Das, S. Stephen, and P. Mathur, “Cancer incidence estimates for 2022 & projection for 2025: Result from National Cancer Registry Programme, India,” Indian J. Med. Res., vol. 156, no. 4, pp. 598–607, Oct. 2022, |
| [5] | S. Malvia et al., “Study of Gene Expression Profiles of Breast Cancers in Indian Women,” Sci. Rep., vol. 9, no. 1, Dec. 2019, |
| [6] | J. Trubek and W. Dissertation, “Cancer Bioinformatics for Biomarker Discovery,” 2017. |
| [7] | N. Cancer Institute, “DIVISION OF CANCER TREATMENT AND DIAGNOSIS,” 2018. |
| [8] | N. S. Fox, “Molecular Cancer Subtypes and Their Associations,” 2021. |
| [9] | J. P. Rennhack et al., “Integrated sequence and gene expression analysis of mouse models of breast cancer reveals critical events with human parallels”, |
| [10] | A. Yazdanparast, “INTEGRATIVE ANALYSIS FOR IDENTIFYING MULTI-LAYER MODULES IN PRECISION MEDICINE,” 2020. |
| [11] | A. Dhillon, A. Singh, and V. K. Bhalla, “A Systematic Review on Biomarker Identification for Cancer Diagnosis and Prognosis in Multi-omics: From Computational Needs to Machine Learning and Deep Learning,” Arch. Comput. Methods Eng., vol. 30, no. 2, pp. 917–949, Mar. 2023, |
| [12] | “Multi-Omic Biomarker Identification and Characterization for Posttraumatic Stress Disorder Citation Terms of Use Share Your Story.” [Online]. Available: |
| [13] | S. Rahman and A. K. Das, “Integrated Multi-omics, Virtual Screening and Molecular Docking Analysis of Methicillin-Resistant Staphylococcus aureus USA300 for the Identification of Potential Therapeutic Targets: An In-Silico Approach,” Int. J. Pept. Res. Ther., vol. 27, no. 4, pp. 2735–2755, Dec. 2021, |
| [14] | N. Gómez-Cebrián, I. Domingo-Ortí, J. L. Poveda, M. J. Vicent, L. Puchades-Carrasco, and A. Pineda-Lucena, “Multi-omic approaches to breast cancer metabolic phenotyping: Applications in diagnosis, prognosis, and the development of novel treatments,” Cancers, vol. 13, no. 18, Sep. 2021, |
| [15] | S. Firdous, A. Ghosh, and S. Saha, “BCSCdb: A database of biomarkers of cancer stem cells,” Database, vol. 2022, 2022, |
| [16] | Y. Shen et al., “Identification of Potential Biomarkers for Thyroid Cancer Using Bioinformatics Strategy: A Study Based on GEO Datasets,” BioMed Res. Int., vol. 2020, 2020, |
| [17] | B. Xie, Z. Yuan, Y. Yang, Z. Sun, S. Zhou, and X. Fang, “MOBCdb: a comprehensive database integrating multi-omics data on breast cancer for precision medicine,” Breast Cancer Res. Treat., vol. 169, no. 3, pp. 625–632, Jun. 2018, |
| [18] | L. M. Mcintyre et al., “GAIT-GM: Galaxy tools for modeling metabolite changes as a function of gene expression”, |
| [19] | M. Leclercq et al., “Large-scale automatic feature selection for biomarker discovery in high-dimensional omics data,” Front. Genet., vol. 10, no. MAY, 2019, |
| [20] | J. Thaiparambil et al., “Integrative metabolomics and transcriptomics analysis reveals novel therapeutic vulnerabilities in lung cancer,” Cancer Med., vol. 12, no. 1, pp. 584–596, Jan. 2023, |
| [21] | A. Awasthi, “Applications of Quantitative Proteomics and Phosphoproteomics to Study the Development of Resistance to Targeted Therapy in Cancer Item Type dissertation,” 2018. [Online]. Available: |
| [22] | S. Misener, S. A. Krawetz, and D. D. Womble, “Bioinformatics Methods and Protocols Methods in Molecular Biology Methods in Molecular Biology TM TM VOLUME 132 HUMANA PRESS HUMANA PRESS Bioinformatics Methods and Protocols The Wisconsin Package of Sequence Analysis Programs.” [Online]. Available: |
| [23] |
Koppad S, B A, Gkoutos GV, Acharjee A. Cloud Computing Enabled Big Multi-Omics Data Analytics. Bioinform Biol Insights. 2021 Jul 28; 15: 11779322211035921.
https://doi.org/10.1177/11779322211035921 PMID: 34376975; PMCID: PMC8323418. |
| [24] |
AWS. (2024, January). HealthOmics: Transform genomic, transcriptomic, and other omics data into insights. Retrieved from
https://docs.aws.amazon.com/omics/latest/dev/what-is-service.html |
| [25] | N. G. Alharbi, “Interactive Visualization of Molecular Dynamics Simulation Data,” 2020. |
| [26] | X. Zhang, “Learning from Multi-Omics Data of Cancer,” 2021. |
| [27] | R. Diaz-Uriarte et al., “Ten quick tips for biomarker discovery and validation analyses using machine learning,” PLoS Comput. Biol., vol. 18, no. 8, Aug. 2022, |
| [28] | X. Zeng, G. Shi, Q. He, and P. Zhu, “Screening and predicted value of potential biomarkers for breast cancer using bioinformatics analysis,” Sci. Rep., vol. 11, no. 1, Dec. 2021, |
| [29] | A. Al-Fatlawi et al., “Netrank: network-based approach for biomarker discovery,” BMC Bioinformatics, vol. 24, no. 1, Dec. 2023, |
| [30] | Z. Z. Hu et al., “Omics-Based Molecular Target and Biomarker Identification,” in Methods in Molecular Biology, vol. 719, Humana Press Inc., 2011, pp. 547–571. |
APA Style
Subramanian, G., Ramamoorthy, K. (2024). From Data to Diagnosis Exploring AWS Cloud Solutions in Multi-Omics Breast Cancer Biomarker Research. Computational Biology and Bioinformatics, 12(1), 1-11. https://doi.org/10.11648/j.cbb.20241201.11
ACS Style
Subramanian, G.; Ramamoorthy, K. From Data to Diagnosis Exploring AWS Cloud Solutions in Multi-Omics Breast Cancer Biomarker Research. Comput. Biol. Bioinform. 2024, 12(1), 1-11. doi: 10.11648/j.cbb.20241201.11
AMA Style
Subramanian G, Ramamoorthy K. From Data to Diagnosis Exploring AWS Cloud Solutions in Multi-Omics Breast Cancer Biomarker Research. Comput Biol Bioinform. 2024;12(1):1-11. doi: 10.11648/j.cbb.20241201.11
@article{10.11648/j.cbb.20241201.11,
author = {Gnanam Subramanian and Kavitha Ramamoorthy},
title = {From Data to Diagnosis Exploring AWS Cloud Solutions in Multi-Omics Breast Cancer Biomarker Research
},
journal = {Computational Biology and Bioinformatics},
volume = {12},
number = {1},
pages = {1-11},
doi = {10.11648/j.cbb.20241201.11},
url = {https://doi.org/10.11648/j.cbb.20241201.11},
eprint = {https://article.sciencepublishinggroup.com/pdf/10.11648.j.cbb.20241201.11},
abstract = {Breast cancer presents a profound global health challenge, compounded by unique intricacies within the Indian demographic, necessitating bespoke research methodologies. This abstract delineates the profound impact of Amazon Web Services (AWS) Cloud Solutions on advancing multi-omics breast cancer biomarker research, with a particular focus on Indian patient cohorts. It initiates with an exposition of the inherent challenges encountered during the transition from raw data acquisition to clinical diagnosis, emphasizing the indispensable role of cloud-based infrastructures in expediting this complex trajectory. Harnessing the comprehensive capabilities of AWS, this study elucidates how cloud solutions facilitate the seamless integration and analysis of multifaceted omics datasets, encompassing genomics, transcriptomics, proteomics, and metabolomics. Central to this endeavor is a meticulous exploration of region-specific molecular markers germane to breast cancer within the Indian populace, illuminating their diagnostic and therapeutic ramifications. By capitalizing on AWS Cloud's scalability and computational acumen, this research underscores notable efficiency enhancements in processing voluminous datasets and distilling salient patterns therein. Furthermore, the discourse extends to the broader ramifications of these technological advancements within the precision medicine landscape, emphasizing the potential for tailored therapeutic interventions. This research heralds a paradigmatic shift in the application of cloud-based infrastructures to unravel the intricate tapestry of breast cancer, transcending geographical confines. Through its provision of insights poised to augment diagnostic precision and therapeutic efficacy on a global scale, this study marks a seminal stride towards fully harnessing the potential of precision oncology in combating breast malignancies.
},
year = {2024}
}
TY - JOUR T1 - From Data to Diagnosis Exploring AWS Cloud Solutions in Multi-Omics Breast Cancer Biomarker Research AU - Gnanam Subramanian AU - Kavitha Ramamoorthy Y1 - 2024/08/15 PY - 2024 N1 - https://doi.org/10.11648/j.cbb.20241201.11 DO - 10.11648/j.cbb.20241201.11 T2 - Computational Biology and Bioinformatics JF - Computational Biology and Bioinformatics JO - Computational Biology and Bioinformatics SP - 1 EP - 11 PB - Science Publishing Group SN - 2330-8281 UR - https://doi.org/10.11648/j.cbb.20241201.11 AB - Breast cancer presents a profound global health challenge, compounded by unique intricacies within the Indian demographic, necessitating bespoke research methodologies. This abstract delineates the profound impact of Amazon Web Services (AWS) Cloud Solutions on advancing multi-omics breast cancer biomarker research, with a particular focus on Indian patient cohorts. It initiates with an exposition of the inherent challenges encountered during the transition from raw data acquisition to clinical diagnosis, emphasizing the indispensable role of cloud-based infrastructures in expediting this complex trajectory. Harnessing the comprehensive capabilities of AWS, this study elucidates how cloud solutions facilitate the seamless integration and analysis of multifaceted omics datasets, encompassing genomics, transcriptomics, proteomics, and metabolomics. Central to this endeavor is a meticulous exploration of region-specific molecular markers germane to breast cancer within the Indian populace, illuminating their diagnostic and therapeutic ramifications. By capitalizing on AWS Cloud's scalability and computational acumen, this research underscores notable efficiency enhancements in processing voluminous datasets and distilling salient patterns therein. Furthermore, the discourse extends to the broader ramifications of these technological advancements within the precision medicine landscape, emphasizing the potential for tailored therapeutic interventions. This research heralds a paradigmatic shift in the application of cloud-based infrastructures to unravel the intricate tapestry of breast cancer, transcending geographical confines. Through its provision of insights poised to augment diagnostic precision and therapeutic efficacy on a global scale, this study marks a seminal stride towards fully harnessing the potential of precision oncology in combating breast malignancies. VL - 12 IS - 1 ER -
Department of Biotechnology, Periyar University, Salem, India
Department of Biotechnology, Periyar University, Salem, India
Information