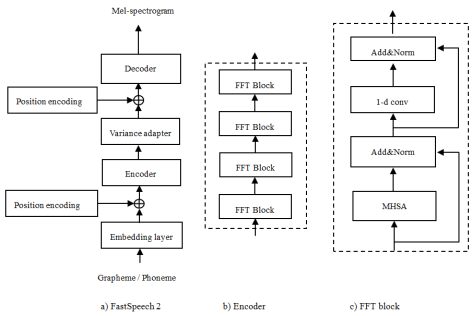
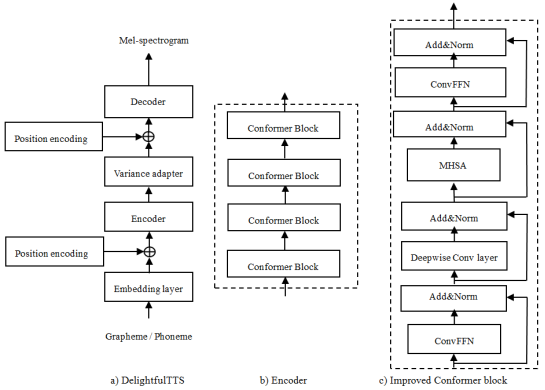
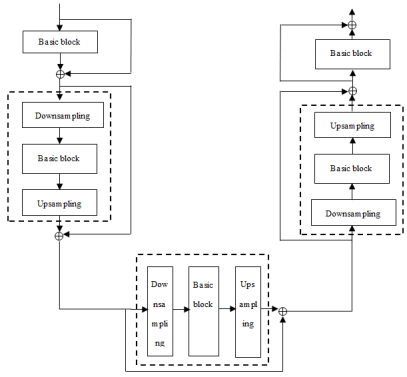
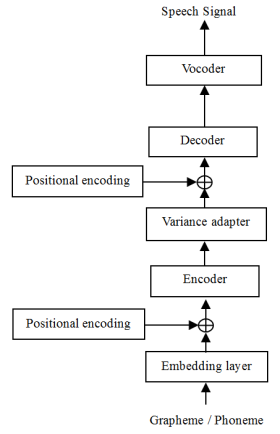
In the end-to-end Text-to-speech synthesis, the ability of acoustic model has important effects on the quality of the speech generated. In the acoustic model, the encoder and decoder are critical components, and usually Transformer is used. The previous works have a lack of ability to model the essential features of speech signal, as they model fixed length of features. There is also limitation of slow inference speed of the acoustic model due to the characteristics of the transformer including the high-computational multi-head self-attention layer. This limits the application of TTS in the low performance of devices such as embedded devices or mobile phones. In this paper, we propose a novel acoustic model to model the different length of features and improve the speed of generating synthetic speech and naturalness as compared to the conventional Transformer structure. Through the experiment, we confirmed that the proposed method improves the naturalness of synthetic speech and operation speed in the low performance of devices.
| Published in | American Journal of Neural Networks and Applications (Volume 11, Issue 1) |
| DOI | 10.11648/j.ajnna.20251101.13 |
| Page(s) | 28-34 |
| Creative Commons |
This is an Open Access article, distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution and reproduction in any medium or format, provided the original work is properly cited. |
| Copyright |
Copyright © The Author(s), 2025. Published by Science Publishing Group |
Text-To-Speech Synthesis, Encoder, Vocoder, Transformer
Hyperparameter | Value |
|---|---|
Phoneme embedding size | 256 |
Number of layers in encoder | 5 |
Number of attention heads in encoder | 2, 2, 2, 2, 2 |
Attention dimension | 96, 96, 96, 96, 96 |
Encoder dimension | 128, 128, 128, 128 128 |
Downsampling rates in encoder | 1, 2, 4, 2, 1 |
Filter sizes | 31, 31, 31, 31, 31 |
Nummber of layers in decoder | 4 |
Number of attention heads in decoder | 2, 2, 2, 2 |
Downsampling rates in decoder | 1, 2, 4, 2 |
Dropout rate | 0.1 |
Method | MOS |
|---|---|
GT | 4.46 |
FastSpeech 2 Mel+MB-MelGAN | 4.18±0.08 |
DelightfulTTS Mel+MB-MelGAN | 4.31±0.05 |
Proposed model Mel+MB-MelGAN | 4.36±0.06 |
Method | RTF | Model size (M) |
|---|---|---|
FastSpeech 2 | 1.62 | 27.4 |
DelightfulTTS | 1.89 | 29.5 |
Proposed method | 0.85 | 18.2 |
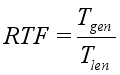 (1)
(1) Method | CMOS | RTF |
|---|---|---|
Proposed method (Applied downsampling and upsampling) | 4.36±0.06 | 0.85 |
Proposed method (Eliminated downsampling and upsampliing) | 4.26±0.09 | 1.21 |
ASR | Automatic Speech Recognition |
CNN | Convolutional Neural Network |
FFT | Feed Forward Transformer |
MHSA | Multi-Head Self-Attention |
MOS | Mean Opinion Score |
RTF | Real Time Factor |
STFT | Short Time Fourier Transform |
TTS | Text-to-Speech |
| [1] | Dai, Z., Yang. Z., Yang, Y., Carbonell, J., Le, Q. V., & Salakhutdinov, R. (2019). Transformer-xl: Attentive language models beyond a fixed-length context. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. |
| [2] | Fan, Y., Qian, Y., Xie, F.-L., & Soong, F. K. (2014). Tts synthesis with bidirectional lstm based recurrent neural networks. In Fifteenth annual conference of the international speech communication association. |
| [3] | Gulati, A., Qin, J., Chiu, C.-C., Parmar, N., Zhang, Y., Yu, J., Han, W., Wang, S., Zhang, Z., Wu, Y. (2020). Conformer: Convolution augmented transformer for speech recognition. In Proceedings of Interspeech. |
| [4] | Han, C.‑J., Ri, U.‑C., Mun, S.‑I., Jang, K.‑S., Han, S.‑Y. (2022). An end‑to‑end TTS model with pronunciation predictor, International Journal of Speech Technology. |
| [5] | Li, N., Liu, S., Liu, Y., Zhao, S., & Liu, M. (2019) Neural speech synthesis with transformer network. In Proceedings of the AAAI conference on artificial intelligence, Vol. 33, (pp. 6706– 6713). |
| [6] | Li, N., Liu, Y., Wu, Y., Liu, S., Zhao, S., & Liu, M. (2020). Robutrans: A robust transformer-based text-to-speech model. In Proceedings of the AAAI conference on artificial intelligence, Vol. 34, (pp. 8228–8235). |
| [7] | Liu. Y., Xu. Z., Wang. G., Chen. K., Li. B., Tan. X., Li. J., He. L., & Zhao. S. (2021). Delightfultts: The microsoft speech synthesis system for blizzard challenge 2021. In Proceedings of the blizzard challenge 2021. |
| [8] | Liu, Y., Xue, R., He, L., Tan, X., & Zhao, S. (2022). DelightfulTTS 2: End-to-end speech synthesis with adversarial vector-quantized auto-encoders. In Proceedings of Interspeech. |
| [9] | Luo, R., Tan, X., Wang, R., Qin, T., Li, J., Zhao, S., Chen, E., & Liu, T. Y. (2021). Lightspeech: Lightweight and fast text to speech with neural architecture search. In Proceedings of international conference on acoustics, speech and signal processing (ICASSP). |
| [10] | Mu, Z., Yang, X., & Dong, Y. (2021). Review of end-to-end speech synthesis technology based on deep learning. International Conference on Secure Cyber Computing and Communications (ICSCCC). |
| [11] | Oord, A. V. D., Dieleman, S., Zen, H., Simonyan, K., Vinyals, O., Graves, A., Kalchbrenner, N., Senior, A., & Kavukcuoglu, K. (2016). WaveNet: A generative model for raw audio. In 9th ISCA speech synthesis workshop (pp. 125–125). |
| [12] | Ren, Y., Hu C., Tan, X., Qin, T., Zhao, S., Zhao, Z., & Liu, T.-Y. (2021). Fastspeech 2: Fast and high-quality end-to-end text to speech. In Proceedings of international conference on learning representations (ICLR 2021). |
| [13] | Ren, Y., Ruan, Y., Tan, X., Qin, T., Zhao, S., Zhao, Z., & Liu, T.-Y. (2019). Fastspeech: Fast, robust and controllable text to speech. In NeurIPS. |
| [14] | Shen, J., Pang, R., Weiss, R. J., Schuster, M., Jaitly, N., Yang, Z., Chen, Z., Zhang, Y., Wang, Y., (2018). Natural tts synthesis by conditioning wavenet on mel spectrogram predictions. In Proceedings of international conference on acoustics, speech and signal processing (ICASSP 2018). (pp. 4779– 4783). |
| [15] | Tan, X., Qin, T., Soong, F., & Liu, T.-Y. (2021). A survey on neural speech synthesis. arXiv preprint arXiv: 2106.15561. |
| [16] | Tokuda, K., Yoshimura, T., Masuko, T., Kobayashi, T., & Kitamura, T. (2000). Speech parameter generation algorithms for hmm-based speech synthesis. In Proceedings of international conference on acoustics, speech and signal processing (ICASSP 2000) (pp. 1315–1318). |
| [17] | Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., Kaiser, Ł., & Polosukhin, I. (2017). Attention is all you need. In Advances in neural information processing systems (pp. 5998–6008). |
| [18] | Xu, Z., Zhang, S., Wang, X., Zhang, J., Wei, W., He, L., Zhao, S. (2023). MuLanTTS: The Microsoft Speech Synthesis System for Blizzard Challenge 2023. In Proceedings of the blizzard challenge 2023. |
| [19] | Yang, G., Yang, S., Liu, K., Fang, P., Chen, W., & Xie, L. (2020). Multi-band melgan: Faster waveform generation for high-quality text-to-speech. In Proceedings of Spoken Language Technology Workshop (SLT). |
| [20] | Ze, H., Senior, A., & Schuster, M. (2013). Statistical parametric speech synthesis using deep neural networks. In Proceedings of international conference on acoustics, speech and signal processing (ICASSP 2013) (pp. 7962–7966). |
APA Style
Song, J., Jong, S., Kim, T., Kim, G., Hong, H. (2025). A Fast Acoustic Model Based on Multi-Scale Feature Fusion Module for Text-To-Speech Synthesis. American Journal of Neural Networks and Applications, 11(1), 28-34. https://doi.org/10.11648/j.ajnna.20251101.13
ACS Style
Song, J.; Jong, S.; Kim, T.; Kim, G.; Hong, H. A Fast Acoustic Model Based on Multi-Scale Feature Fusion Module for Text-To-Speech Synthesis. Am. J. Neural Netw. Appl. 2025, 11(1), 28-34. doi: 10.11648/j.ajnna.20251101.13
@article{10.11648/j.ajnna.20251101.13,
author = {Jin-Hyok Song and Song-Chol Jong and Thae-Myong Kim and Guk-Chol Kim and Hakho Hong},
title = {A Fast Acoustic Model Based on Multi-Scale Feature Fusion Module for Text-To-Speech Synthesis
},
journal = {American Journal of Neural Networks and Applications},
volume = {11},
number = {1},
pages = {28-34},
doi = {10.11648/j.ajnna.20251101.13},
url = {https://doi.org/10.11648/j.ajnna.20251101.13},
eprint = {https://article.sciencepublishinggroup.com/pdf/10.11648.j.ajnna.20251101.13},
abstract = {In the end-to-end Text-to-speech synthesis, the ability of acoustic model has important effects on the quality of the speech generated. In the acoustic model, the encoder and decoder are critical components, and usually Transformer is used. The previous works have a lack of ability to model the essential features of speech signal, as they model fixed length of features. There is also limitation of slow inference speed of the acoustic model due to the characteristics of the transformer including the high-computational multi-head self-attention layer. This limits the application of TTS in the low performance of devices such as embedded devices or mobile phones. In this paper, we propose a novel acoustic model to model the different length of features and improve the speed of generating synthetic speech and naturalness as compared to the conventional Transformer structure. Through the experiment, we confirmed that the proposed method improves the naturalness of synthetic speech and operation speed in the low performance of devices.
},
year = {2025}
}
TY - JOUR T1 - A Fast Acoustic Model Based on Multi-Scale Feature Fusion Module for Text-To-Speech Synthesis AU - Jin-Hyok Song AU - Song-Chol Jong AU - Thae-Myong Kim AU - Guk-Chol Kim AU - Hakho Hong Y1 - 2025/04/22 PY - 2025 N1 - https://doi.org/10.11648/j.ajnna.20251101.13 DO - 10.11648/j.ajnna.20251101.13 T2 - American Journal of Neural Networks and Applications JF - American Journal of Neural Networks and Applications JO - American Journal of Neural Networks and Applications SP - 28 EP - 34 PB - Science Publishing Group SN - 2469-7419 UR - https://doi.org/10.11648/j.ajnna.20251101.13 AB - In the end-to-end Text-to-speech synthesis, the ability of acoustic model has important effects on the quality of the speech generated. In the acoustic model, the encoder and decoder are critical components, and usually Transformer is used. The previous works have a lack of ability to model the essential features of speech signal, as they model fixed length of features. There is also limitation of slow inference speed of the acoustic model due to the characteristics of the transformer including the high-computational multi-head self-attention layer. This limits the application of TTS in the low performance of devices such as embedded devices or mobile phones. In this paper, we propose a novel acoustic model to model the different length of features and improve the speed of generating synthetic speech and naturalness as compared to the conventional Transformer structure. Through the experiment, we confirmed that the proposed method improves the naturalness of synthetic speech and operation speed in the low performance of devices. VL - 11 IS - 1 ER -
Institute of Mathematics, State Academy of Sciences, Pyongyang, Democratic People’s Republic of Korea
Institute of Mathematics, State Academy of Sciences, Pyongyang, Democratic People’s Republic of Korea
Institute of Mathematics, State Academy of Sciences, Pyongyang, Democratic People’s Republic of Korea
Institute of Mathematics, State Academy of Sciences, Pyongyang, Democratic People’s Republic of Korea
Institute of Mathematics, State Academy of Sciences, Pyongyang, Democratic People’s Republic of Korea
Information